
-
18 Présentation
-
18.1 Échantillonneurs
- Requête FTP
- Requête HTTP
- Requête JDBC
- Requête Java
- Requête LDAP
- Requête étendue LDAP
- Accéder à l'échantillonneur de journaux
- Échantillonneur BeanShell
- Échantillonneur JSR223
- Échantillonneur TCP
- Éditeur JMS
- Abonné JMS
- Point à point JMS
- Requête JUnit
- Échantillonneur de lecteur de courrier
- Action de contrôle de flux (auparavant : Action de test )
- Échantillonneur SMTP
- Échantillonneur de processus de système d'exploitation
- Script MongoDB (obsolète)
- Demande de boulon
-
18.2 Contrôleurs logiques
- Contrôleur simple
- Contrôleur de boucle
- Une seule fois contrôleur
- Contrôleur d'entrelacement
- Contrôleur aléatoire
- Contrôleur d'ordre aléatoire
- Contrôleur de débit
- Contrôleur d'exécution
- Si contrôleur
- Pendant que le contrôleur
- Contrôleur de commutateur
- Pour chaque contrôleur
- Contrôleur de modules
- Inclure le contrôleur
- Contrôleur de transactions
- Contrôleur d'enregistrement
- Contrôleur de section critique
-
18.3 Auditeurs
- Exemple de configuration de sauvegarde des résultats
- Résultats du graphique
- Résultats d'assertion
- Afficher l'arborescence des résultats
- Rapport agrégé
- Afficher les résultats dans le tableau
- Rédacteur de données simple
- Graphique agrégé
- Graphique du temps de réponse
- Visualiseur de courrier
- Écouteur BeanShell
- Rapport sommaire
- Enregistrer les réponses dans un fichier
- Auditeur JSR223
- Générer des résultats récapitulatifs
- Visualiseur d'assertion de comparaison
- Écouteur principal
-
18.4 Éléments de configuration
- Configuration de l'ensemble de données CSV
- Valeurs par défaut des requêtes FTP
- Gestionnaire de cache DNS
- Gestionnaire d'autorisations HTTP
- Gestionnaire de cache HTTP
- Gestionnaire de cookies HTTP
- Valeurs par défaut des requêtes HTTP
- Gestionnaire d'en-tête HTTP
- Valeurs par défaut des requêtes Java
- Configuration de la connexion JDBC
- Configuration du magasin de clés
- Élément de configuration de connexion
- Valeurs par défaut des requêtes LDAP
- Valeurs par défaut des requêtes étendues LDAP
- Configuration de l'échantillonneur TCP
- Variables définies par l'utilisateur
- Variable aléatoire
- Compteur
- Élément de configuration simple
- Configuration de la source MongoDB (obsolète)
- Configuration de connexion de boulon
- 18.5 Assertions
- 18.6 Minuteries
- 18.7 Préprocesseurs
-
18.8 Post-processeurs
- Extracteur d'expressions régulières
- Extracteur de sélecteur CSS (auparavant : Extracteur CSS/JQuery )
- Extracteur XPath2
- Extracteur XPath
- Extracteur JSON JMESPath
- Gestionnaire d'action d'état de résultat
- Post-processeur BeanShell
- Post-processeur JSR223
- Post-processeur JDBC
- Extracteur JSON
- Extracteur de frontière
-
18.9 Fonctionnalités diverses
- Plan de test
- Groupe de fils
- Table de travail
- Gestionnaire SSL
- Enregistreur de script de test HTTP(S) (anciennement : serveur proxy HTTP)
- Serveur miroir HTTP
- Affichage des propriétés
- Échantillonneur de débogage
- Déboguer le post-processeur
- Fragment d'essai
- configurer le groupe de threads
- Groupe de threads démontage
18 Introduction ¶
18.1 Échantillonneurs ¶
Les échantillonneurs effectuent le travail réel de JMeter. Chaque échantillonneur (à l'exception de Flow Control Action ) génère un ou plusieurs résultats d'échantillon. Les résultats de l'échantillon ont divers attributs (succès/échec, temps écoulé, taille des données, etc.) et peuvent être visualisés dans les différents écouteurs.
Requête FTP ¶
La latence est définie sur le temps nécessaire pour se connecter.

Paramètres ¶
Requête HTTP ¶
Cet échantillonneur vous permet d'envoyer une requête HTTP/HTTPS à un serveur Web. Il vous permet également de contrôler si JMeter analyse ou non les fichiers HTML à la recherche d'images et d'autres ressources intégrées et envoie des requêtes HTTP pour les récupérer. Les types de ressources intégrées suivants sont récupérés :
- images
- applets
- feuilles de style (CSS) et ressources référencées à partir de ces fichiers
- scripts externes
- cadres, iframes
- images de fond (corps, table, TD, TR)
- fond sonore
L'analyseur par défaut est org.apache.jmeter.protocol.http.parser.LagartoBasedHtmlParser . Cela peut être changé en utilisant la propriété " htmlparser.className " - voir jmeter.properties pour plus de détails.
Si vous envisagez d'envoyer plusieurs requêtes au même serveur Web, envisagez d'utiliser un élément de configuration HTTP Request Defaults afin de ne pas avoir à saisir les mêmes informations pour chaque requête HTTP.
Ou, au lieu d'ajouter manuellement des requêtes HTTP, vous pouvez utiliser l' enregistreur de script de test HTTP(S) de JMeter pour les créer. Cela peut vous faire gagner du temps si vous avez beaucoup de requêtes HTTP ou des requêtes avec de nombreux paramètres.
Trois éléments de test différents sont utilisés pour définir les échantillonneurs :
- Échantillonneur AJP/1.3
- utilise le protocole Tomcat mod_jk (permet de tester Tomcat en mode AJP sans avoir besoin d'Apache httpd) L'échantillonneur AJP ne prend pas en charge le téléchargement de plusieurs fichiers ; seul le premier fichier sera utilisé.
- Requête HTTP
- cela a une liste déroulante d'implémentation, qui sélectionne l'implémentation du protocole HTTP à utiliser :
- Java
- utilise l'implémentation HTTP fournie par la JVM. Cela présente certaines limitations par rapport aux implémentations HttpClient - voir ci-dessous.
- HTTPClient4
- utilise Apache HttpComponents HttpClient 4.x.
- Valeur vide
- ne définit pas l'implémentation sur les échantillonneurs HTTP, s'appuie donc sur les valeurs par défaut de la requête HTTP si elles sont présentes ou sur la propriété jmeter.httpsampler définie dans jmeter.properties
- Requête HTTP GraphQL
- il s'agit d'une variante GUI de la requête HTTP pour fournir des éléments d'interface utilisateur plus pratiques pour afficher ou modifier GraphQL Query , Variables et Operation Name , tout en les convertissant automatiquement en arguments HTTP sous le capot à l'aide du même échantillonneur. Cela masque ou personnalise les éléments d'interface utilisateur suivants car ils sont moins pratiques ou non pertinents pour GraphQL sur les requêtes HTTP/HTTPS :
- Méthode : Seules les méthodes POST et GET sont disponibles conformément à la spécification GraphQL sur HTTP. La méthode POST est sélectionnée par défaut.
- Paramètres et onglets Post Body : vous pouvez afficher ou modifier le contenu des paramètres via les éléments d'interface utilisateur Requête, Variables et Nom de l'opération à la place.
- Onglet Téléchargement de fichier : non pertinent pour les requêtes GraphQL.
- Ressources intégrées à partir de la section Fichiers HTML dans l'onglet Avancé : non pertinent dans les réponses GraphQL JSON.
L'implémentation Java HTTP présente certaines limitations :
- Il n'y a aucun contrôle sur la façon dont les connexions sont réutilisées. Lorsqu'une connexion est libérée par JMeter, elle peut ou non être réutilisée par le même thread.
- L'API est mieux adaptée à une utilisation à un seul thread - divers paramètres sont définis via les propriétés du système et s'appliquent donc à toutes les connexions.
- Pas de prise en charge de l'authentification Kerberos
- Il ne prend pas en charge les tests de certificats basés sur le client avec Keystore Config.
- Meilleur contrôle du mécanisme Retry
- Il ne prend pas en charge les hôtes virtuels.
- Il ne prend en charge que les méthodes suivantes : GET , POST , HEAD , OPTIONS , PUT , DELETE et TRACE
- Meilleur contrôle sur la mise en cache DNS avec DNS Cache Manager
Si la demande nécessite une autorisation de connexion au serveur ou au proxy (c'est-à-dire lorsqu'un navigateur créerait une boîte de dialogue contextuelle), vous devrez également ajouter un élément de configuration HTTP Authorization Manager . Pour les connexions normales (c'est-à-dire lorsque l'utilisateur entre les informations de connexion dans un formulaire), vous devrez déterminer ce que fait le bouton d'envoi du formulaire et créer une requête HTTP avec la méthode appropriée (généralement POST ) et les paramètres appropriés à partir de la définition du formulaire. . Si la page utilise HTTP, vous pouvez utiliser le proxy JMeter pour capturer la séquence de connexion.
Un contexte SSL distinct est utilisé pour chaque thread. Si vous souhaitez utiliser un seul contexte SSL (pas le comportement standard des navigateurs), définissez la propriété JMeter :
https.sessioncontext.shared=truePar défaut, depuis la version 5.0, le contexte SSL est conservé lors d'une itération de groupe de threads et réinitialisé à chaque itération de test. Si, dans votre plan de test, le même utilisateur itère plusieurs fois, vous devez le définir sur false.
httpclient.reset_state_on_thread_group_iteration=true
https.default.protocol=SSLv3
JMeter permet également d'activer des protocoles supplémentaires, en modifiant la propriété https.socket.protocols .
Si la requête utilise des cookies, vous aurez également besoin d'un HTTP Cookie Manager . Vous pouvez ajouter l'un ou l'autre de ces éléments au groupe de threads ou à la requête HTTP. Si vous avez plusieurs requêtes HTTP nécessitant des autorisations ou des cookies, ajoutez les éléments au groupe de threads. De cette façon, tous les contrôleurs de requête HTTP partageront les mêmes éléments du gestionnaire d'autorisations et du gestionnaire de cookies.
Si la requête utilise une technique appelée « réécriture d'URL » pour maintenir les sessions, consultez la section 6.1 Gestion des sessions utilisateur avec la réécriture d'URL pour des étapes de configuration supplémentaires.




Paramètres ¶
- il est fourni par HTTP Request Defaults
- ou une URL complète comprenant le schéma, l'hôte et le port ( schema://host:port ) est définie dans le champ Path
Une assertion de durée peut être utilisée pour détecter les réponses qui prennent trop de temps à se terminer.
D'autres méthodes peuvent être prédéfinies pour HttpClient4 en utilisant la propriété JMeter httpsampler.user_defined_methods .
"Redirection demandée mais followRedirects est désactivé"Cela peut être ignoré.
JMeter réduira les chemins de la forme ' /../segment ' dans les URL de redirection absolues et relatives. Par exemple , http://host/one/../two sera réduit à http://host/two . Si nécessaire, ce comportement peut être supprimé en définissant la propriété JMeter httpsampler.redirect.removeslashdotdot=false
De plus, vous pouvez spécifier si chaque paramètre doit être encodé en URL. Si vous n'êtes pas sûr de ce que cela signifie, il est probablement préférable de le sélectionner. Si vos valeurs contiennent des caractères tels que les suivants, un encodage est généralement requis :
- Caractères de contrôle ASCII
- Caractères non ASCII
- Caractères réservés : les URL utilisent certains caractères pour une utilisation spéciale dans la définition de leur syntaxe. Lorsque ces caractères ne sont pas utilisés dans leur rôle spécial à l'intérieur d'une URL, ils doivent être encodés, exemple : ' $ ', ' & ', ' + ', ' , ' , ' / ', ' : ', ' ; ', ' = ', ' ? ', ' @ '
- Caractères dangereux : certains caractères présentent la possibilité d'être mal compris dans les URL pour diverses raisons. Ces caractères doivent également toujours être codés, exemple : ' ', ' < ', ' > ', ' # ', ' % ', …
S'il s'agit d'une requête POST ou PUT ou PATCH et qu'il existe un seul fichier dont l'attribut 'Nom du paramètre' (ci-dessous) est omis, alors le fichier est envoyé en tant que corps entier de la requête, c'est-à-dire qu'aucun wrapper n'est ajouté. Cela permet d'envoyer des corps arbitraires. Cette fonctionnalité est présente pour les requêtes POST , ainsi que pour les requêtes PUT . Voir ci-dessous pour plus d'informations sur la gestion des paramètres.
Pour distinguer la valeur de l'adresse source, sélectionnez le type de celles-ci :
- Sélectionnez IP/Hostname pour utiliser une adresse IP spécifique ou un nom d'hôte (local)
- Sélectionnez Périphérique pour choisir la première adresse disponible pour cette interface, qui peut être IPv4 ou IPv6
- Sélectionnez Device IPv4 pour sélectionner l'adresse IPv4 du nom de l'appareil (comme eth0 , lo , em0 , etc.)
- Sélectionnez Device IPv6 pour sélectionner l'adresse IPv6 du nom de l'appareil (comme eth0 , lo , em0 , etc.)
Cette propriété est utilisée pour activer l'usurpation d'adresse IP. Il remplace l'adresse IP locale par défaut pour cet exemple. L'hôte JMeter doit avoir plusieurs adresses IP (c'est-à-dire des alias IP, des interfaces réseau, des périphériques). La valeur peut être un nom d'hôte, une adresse IP ou un périphérique d'interface réseau tel que " eth0 " ou " lo " ou " wlan0 ".
Si la propriété httpclient.localaddress est définie, elle est utilisée pour toutes les requêtes HttpClient.
Les paramètres suivants sont disponibles uniquement pour la requête HTTP GraphQL :
Paramètres ¶
Gestion des paramètres :
pour les méthodes POST et PUT , s'il n'y a pas de fichier à envoyer et que le ou les noms du ou des paramètres sont omis, le corps est créé en concaténant toutes les valeurs des paramètres. Notez que les valeurs sont concaténées sans ajouter de caractères de fin de ligne. Ceux-ci peuvent être ajoutés en utilisant la fonction __char() dans les champs de valeur. Cela permet d'envoyer des corps arbitraires. Les valeurs sont codées si l'indicateur de codage est défini. Voir également le type MIME ci-dessus pour savoir comment contrôler l' en- tête de demande
de type de contenu qui est envoyé.
Pour les autres méthodes, si le nom du paramètre est manquant, le paramètre est ignoré. Ceci permet l'utilisation de paramètres facultatifs définis par des variables.
Vous avez la possibilité de basculer vers l'onglet Données corporelles lorsqu'une demande n'a que des paramètres sans nom (ou aucun paramètre du tout). Cette option est utile dans les cas suivants (entre autres) :
- Requête HTTP GWT RPC
- Requête HTTP JSON REST
- Requête HTTP REST XML
- Requête HTTP SOAP
En mode Body Data , chaque ligne sera envoyée avec CRLF en annexe, à l'exception de la dernière ligne. Pour envoyer un CRLF après la dernière ligne de données, assurez-vous simplement qu'il y a une ligne vide à la suite. (Cela ne peut pas être vu, sauf en notant si le curseur peut être placé sur la ligne suivante.)



Gestion des méthodes :
les méthodes de requête GET , DELETE , POST , PUT et PATCH fonctionnent de la même manière, sauf qu'à partir de la version 3.1, seule la méthode POST prend en charge les requêtes en plusieurs parties ou le téléchargement de fichiers. Le corps des méthodes PUT et PATCH doit être fourni comme suit :
- définir le corps comme un fichier avec un champ de nom de paramètre vide ; auquel cas le type MIME est utilisé comme type de contenu
- définir le corps en tant que valeur(s) de paramètre sans nom
- utilisez l' onglet Données corporelles
Les méthodes GET , DELETE et POST ont un moyen supplémentaire de passer des paramètres en utilisant l' onglet Paramètres . GET , DELETE , PUT et PATCH nécessitent un Content-Type. Si vous n'utilisez pas de fichier, attachez un gestionnaire d'en-tête à l'échantillonneur et définissez-y le type de contenu.
JMeter analyse les réponses des ressources intégrées. Il utilise la propriété HTTPResponse.parsers , qui est une liste d'identifiants d'analyseur, par exemple htmlParser , cssParser et wmlParser . Pour chaque identifiant trouvé, JMeter vérifie deux propriétés supplémentaires :
- id.types - une liste de types de contenu
- id.className - l'analyseur à utiliser pour extraire les ressources intégrées
Voir le fichier jmeter.properties pour les détails des paramètres. Si la propriété HTTPResponse.parser n'est pas définie, JMeter revient au comportement précédent, c'est-à-dire que seules les réponses text/html seront analysées
Émulation de connexions lentes :HttpClient4 et Java Sampler prennent en charge l'émulation des connexions lentes ; voir les entrées suivantes dans jmeter.properties :
# Définir des caractères par seconde> 0 pour émuler des connexions lentes #httpclient.socket.http.cps=0 #httpclient.socket.https.cps=0Cependant, l' échantillonneur Java ne prend en charge que les connexions HTTPS lentes.
Calcul de la taille de la réponse
L' implémentation HttpClient4 inclut la surcharge dans la taille du corps de la réponse, de sorte que la valeur peut être supérieure au nombre d'octets dans le contenu de la réponse.
Gestion
des nouvelles tentatives Par défaut, la nouvelle tentative a été définie sur 0 pour les implémentations HttpClient4 et Java, ce qui signifie qu'aucune nouvelle tentative n'est tentée.
Pour HttpClient4, le nombre de tentatives peut être remplacé en définissant la propriété JMeter appropriée, par exemple :
httpclient4.retrycount=3
httpclient4.request_sent_retry_enabled=true
http.java.sampler.retries=3
Remarque : Les certificats ne sont pas conformes aux contraintes de l'algorithme
Vous pouvez rencontrer l'erreur suivante : java.security.cert.CertificateException : les certificats ne sont pas conformes aux contraintes de l'algorithme
si vous exécutez une requête HTTPS sur un site Web avec un certificat SSL (lui-même ou l'un des certificats SSL dans sa chaîne de confiance) avec un algorithme de signature utilisant MD2 (comme md2WithRSAEncryption ) ou avec un certificat SSL de taille inférieure à 1024 bits.
Cette erreur est liée à une sécurité accrue dans Java 8.
Pour vous permettre d'effectuer votre requête HTTPS, vous pouvez rétrograder la sécurité de votre installation Java en modifiant la propriété Java jdk.certpath.disabledAlgorithms . Supprimez la valeur MD2 ou la contrainte de taille, selon votre cas.
Cette propriété est dans ce fichier :
JAVA_HOME/jre/lib/security/java.security
Voir le bogue 56357 pour plus de détails.
- Affirmation
- Construire un plan de test Web
- Construire un plan de test Web avancé
- Gestionnaire d'autorisations HTTP
- Gestionnaire de cookies HTTP
- Gestionnaire d'en-tête HTTP
- Analyseur de lien HTML
- Enregistreur de script de test HTTP(S)
- Valeurs par défaut des requêtes HTTP
- Requêtes HTTP et ID de session : réécriture d'URL
Requête JDBC ¶
Cet échantillonneur vous permet d'envoyer une requête JDBC (une requête SQL) à une base de données.
Avant de l'utiliser, vous devez configurer un élément de configuration de la configuration de la connexion JDBC
Si la liste des noms de variables est fournie, pour chaque ligne renvoyée par une instruction Select, les variables sont définies avec la valeur de la colonne correspondante (si un nom de variable est fourni) et le nombre de lignes est également défini. Par exemple, si l'instruction Select renvoie 2 lignes de 3 colonnes et que la liste de variables est A,,C , alors les variables suivantes seront configurées :
A_#=2 (nombre de lignes) A_1=colonne 1, ligne 1 A_2=colonne 1, ligne 2 C_#=2 (nombre de lignes) C_1=colonne 3, ligne 1 C_2=colonne 3, ligne 2
Si l'instruction Select renvoie zéro ligne, les variables A_# et C_# seraient définies sur 0 et aucune autre variable ne serait définie.
Les anciennes variables sont effacées si nécessaire - par exemple, si la première sélection récupère six lignes et qu'une seconde sélection ne renvoie que trois lignes, les variables supplémentaires pour les lignes quatre, cinq et six seront supprimées.

Paramètres ¶
- Sélectionnez le relevé
- Déclaration de mise à jour - utilisez-la également pour les insertions et les suppressions
- Déclaration appelable
- Instruction Select préparée
- Déclaration de mise à jour préparée - utilisez-la également pour les insertions et les suppressions
- Commettre
- Retour en arriere
- Validation automatique (faux)
- Validation automatique (vrai)
- Modifier - cela devrait être une référence de variable qui correspond à l'un des éléments ci-dessus
- sélectionnez * parmi t_customers où id=23
-
APPELER SYSCS_UTIL.SYSCS_EXPORT_TABLE (null, ?, ?, null, null, null)
- Valeurs des paramètres : nom de la table , nom du fichier
- Types de paramètres : VARCHAR , VARCHAR
La liste doit être entourée de guillemets doubles si l'une des valeurs contient une virgule ou un guillemet double, et tout guillemet double incorporé doit être doublé, par exemple :
"Dbl-Quote : " et virgule : ,"
Ceux-ci sont définis comme des champs dans la classe java.sql.Types , voir par exemple :
Javadoc pour java.sql.Types .
S'il n'est pas spécifié, " IN " est supposé, c'est-à-dire que " DATE " est identique à " IN DATE ".
Si le type n'est pas l'un des champs trouvés dans java.sql.Types , JMeter accepte également le nombre entier correspondant, par exemple depuis OracleTypes.CURSOR == -10 , vous pouvez utiliser " INOUT -10 ".
Il doit y avoir autant de types qu'il y a d'espaces réservés dans l'instruction.
columnValue = vars.getObject("resultObject").get(0).get("Column Name");
- Stocker en tant que chaîne (par défaut) - Toutes les variables de la liste des noms de variables sont stockées sous forme de chaînes et ne parcourront pas un ResultSet lorsqu'elles sont présentes dans la liste. Les CLOB seront convertis en chaînes. Les BLOB seront convertis en chaînes comme s'il s'agissait d'un tableau d'octets encodé en UTF-8. Les CLOB et les BLOB seront coupés après jdbcsampler.max_retain_result_size octets.
- Stocker en tant qu'objet - Les variables de type ResultSet sur la liste des noms de variables seront stockées en tant qu'objet et pourront être consultées dans les tests/scripts suivants et itérées, ne seront pas itérées dans le ResultSet . Les CLOB seront traités comme si Store As String était sélectionné. Les BLOB seront stockés sous la forme d'un tableau d'octets. Les CLOB et les BLOB seront coupés après jdbcsampler.max_retain_result_size octets.
- Compter les enregistrements - Les variables des types ResultSet seront itérées en affichant le nombre d'enregistrements comme résultat. Les variables seront stockées sous forme de chaînes. Pour les BLOB , la taille de l'objet sera stockée.
Requête Java ¶
Cet échantillonneur vous permet de contrôler une classe Java qui implémente l' interface org.apache.jmeter.protocol.java.sampler.JavaSamplerClient . En écrivant votre propre implémentation de cette interface, vous pouvez utiliser JMeter pour exploiter plusieurs threads, le contrôle des paramètres d'entrée et la collecte de données.
Le menu déroulant fournit la liste de toutes ces implémentations trouvées par JMeter dans son classpath. Les paramètres peuvent ensuite être spécifiés dans le tableau ci-dessous - tels que définis par votre implémentation. Deux exemples simples ( JavaTest et SleepTest ) sont fournis.
L' échantillonneur d'exemple JavaTest peut être utile pour vérifier les plans de test, car il permet de définir des valeurs dans presque tous les champs. Celles-ci peuvent ensuite être utilisées par Assertions, etc. Les champs permettent d'utiliser des variables, de sorte que les valeurs de celles-ci peuvent être facilement vues.

Paramètres ¶
Les paramètres suivants s'appliquent aux implémentations SleepTest et JavaTest :
Paramètres ¶
Le temps de sommeil est calculé comme suit :
totalSleepTime = SleepTime + (System.currentTimeMillis() % SleepMask)
Les paramètres suivants s'appliquent en plus à l' implémentation de JavaTest :
Paramètres ¶
Requête LDAP ¶
Si vous envisagez d'envoyer plusieurs requêtes au même serveur LDAP, envisagez d'utiliser un élément de configuration des valeurs par défaut des requêtes LDAP afin de ne pas avoir à saisir les mêmes informations pour chaque requête LDAP.
De la même manière, l' élément de configuration de connexion utilise également pour la connexion et le mot de passe.
Il existe deux manières de créer des scénarios de test pour tester un serveur LDAP.
- Cas de test intégrés.
- Scénarios de test définis par l'utilisateur.
Il existe quatre scénarios de test de LDAP. Les tests sont donnés ci-dessous :
- Ajouter un essai
- Test intégré :
Cela ajoutera une entrée prédéfinie dans le serveur LDAP et calculera le temps d'exécution. Après l'exécution du test, l'entrée créée sera supprimée du serveur LDAP.
- Test défini par l'utilisateur :
Cela ajoutera l'entrée dans le serveur LDAP. L'utilisateur doit entrer tous les attributs dans la table. Les entrées sont collectées à partir de la table à ajouter. Le temps d'exécution est calculé. L'entrée créée ne sera pas supprimée après le test.
- Test intégré :
- Modifier l'essai
- Test intégré :
Cela créera d'abord une entrée prédéfinie, puis modifiera l'entrée créée dans le serveur LDAP. Et calculera le temps d'exécution. Après l'exécution du test, l'entrée créée sera supprimée du serveur LDAP.
- Test défini par l'utilisateur :
Cela modifiera l'entrée dans le serveur LDAP. L'utilisateur doit entrer tous les attributs dans le tableau. Les entrées sont collectées à partir de la table à modifier. Le temps d'exécution est calculé. L'entrée ne sera pas supprimée du serveur LDAP.
- Test intégré :
- Essai de recherche
- Test intégré :
Cela créera d'abord l'entrée, puis recherchera si les attributs sont disponibles. Il calcule le temps d'exécution de la requête de recherche. À la fin de l'exécution, l'entrée créée sera supprimée du serveur LDAP.
- Test défini par l'utilisateur :
Cela recherchera l'entrée définie par l'utilisateur (filtre de recherche) dans la base de recherche (encore une fois, définie par l'utilisateur). Les entrées doivent être disponibles dans le serveur LDAP. Le temps d'exécution est calculé.
- Test intégré :
- Supprimer l'essai
- Test intégré :
Cela créera d'abord une entrée prédéfinie, puis elle sera supprimée du serveur LDAP. Le temps d'exécution est calculé.
- Test défini par l'utilisateur :
Cela supprimera l'entrée définie par l'utilisateur dans le serveur LDAP. Les entrées doivent être disponibles dans le serveur LDAP. Le temps d'exécution est calculé.
- Test intégré :
Paramètres ¶
Requête étendue LDAP ¶
Si vous envisagez d'envoyer plusieurs requêtes au même serveur LDAP, envisagez d'utiliser un élément de configuration des valeurs par défaut des requêtes étendues LDAP afin de ne pas avoir à saisir les mêmes informations pour chaque requête LDAP.

Neuf opérations de test sont définies. Ces opérations sont données ci-dessous :
- Liaison de fil
-
Toute demande LDAP fait partie d'une session LDAP, la première chose à faire est donc de démarrer une session sur le serveur LDAP. Pour démarrer cette session, un thread bind est utilisé, ce qui équivaut à l'opération " bind " de LDAP. L'utilisateur est invité à donner un nom d' utilisateur (Nom distinctif) et un mot de passe , qui seront utilisés pour lancer une session. Lorsqu'aucun mot de passe ou un mot de passe incorrect n'est spécifié, une session anonyme est lancée. Attention, omettre le mot de passe ne fera pas échouer ce test, un mauvais mot de passe le fera. (NB ceci est stocké non chiffré dans le plan de test)
Paramètres
AttributLa descriptionObligatoireNomNom descriptif de cet échantillonneur affiché dans l'arborescence.NonNom du serveurLe nom (ou l'adresse IP) du serveur LDAP.OuiPortLe numéro de port sur lequel le serveur LDAP écoute. Si cela est omis, JMeter suppose que le serveur LDAP écoute sur le port par défaut (389).NonDNNom distinctif de l'objet de base qui sera utilisé pour toute opération ultérieure. Il peut être utilisé comme point de départ pour toutes les opérations. Vous ne pouvez démarrer aucune opération à un niveau supérieur à ce DN !NonNom d'utilisateurNom distinctif complet de l'utilisateur que vous souhaitez lier.NonMot de passeMot de passe pour l'utilisateur ci-dessus. S'il est omis, il en résultera une liaison anonyme. S'il est incorrect, l'échantillonneur renverra une erreur et reviendra à une liaison anonyme. (NB ceci est stocké non chiffré dans le plan de test)NonDélai de connexion (en millisecondes)Délai d'expiration de la connexion, si dépassé, la connexion sera interrompueNonUtiliser le protocole LDAP sécuriséUtilisez le schéma ldaps:// au lieu de ldap://NonFaire confiance à tous les certificatsFaire confiance à tous les certificats, utilisé uniquement si Utiliser le protocole LDAP sécurisé est cochéNon - Délier le fil
-
C'est simplement l'opération pour terminer une session. C'est l'équivalent de l'opération LDAP « unbind ».
Paramètres
AttributLa descriptionObligatoireNomNom descriptif de cet échantillonneur affiché dans l'arborescence.Non - Liaison/déliaison simple
-
Il s'agit d'une combinaison des opérations LDAP « bind » et « unbind ». Il peut être utilisé pour une demande d'authentification/vérification du mot de passe pour n'importe quel utilisateur. Il ouvrira une nouvelle session, juste pour vérifier la validité de la combinaison utilisateur/mot de passe, et terminera à nouveau la session.
Paramètres
AttributLa descriptionObligatoireNomNom descriptif de cet échantillonneur affiché dans l'arborescence.NonNom d'utilisateurNom distinctif complet de l'utilisateur que vous souhaitez lier.OuiMot de passeMot de passe pour l'utilisateur ci-dessus. S'il est omis, il en résultera une liaison anonyme. S'il est incorrect, l'échantillonneur renverra une erreur. (NB ceci est stocké non chiffré dans le plan de test)Non - Renommer l'entrée
-
Il s'agit de l'opération LDAP « moddn ». Il peut être utilisé pour renommer une entrée, mais aussi pour déplacer une entrée ou une sous-arborescence complète vers un autre endroit de l'arborescence LDAP.
Paramètres
AttributLa descriptionObligatoireNomNom descriptif de cet échantillonneur affiché dans l'arborescence.NonAncien nom d'entréeLe nom distinctif actuel de l'objet que vous souhaitez renommer ou déplacer, par rapport au DN donné dans l'opération de liaison de thread.OuiNouveau nom distinctifLe nouveau nom distinctif de l'objet que vous souhaitez renommer ou déplacer, par rapport au DN donné dans l'opération de liaison de thread.Oui - Ajouter un test
-
Il s'agit de l'opération « add » LDAP . Il peut être utilisé pour ajouter n'importe quel type d'objet au serveur LDAP.
Paramètres
AttributLa descriptionObligatoireNomNom descriptif de cet échantillonneur affiché dans l'arborescence.NonDN d'entréeNom distinctif de l'objet que vous souhaitez ajouter, par rapport au DN donné dans l'opération de liaison de thread.OuiAjouter un testUne liste d'attributs et leurs valeurs que vous souhaitez utiliser pour l'objet. Si vous devez ajouter un attribut à valeurs multiples, vous devez ajouter plusieurs fois le même attribut avec leurs valeurs respectives à la liste.Oui - Supprimer l'essai
-
C'est l'opération LDAP " delete ", elle peut être utilisée pour supprimer un objet de l'arborescence LDAP
Paramètres
AttributLa descriptionObligatoireNomNom descriptif de cet échantillonneur affiché dans l'arborescence.NonEffacerNom distinctif de l'objet que vous souhaitez supprimer, par rapport au DN donné dans l'opération de liaison de thread.Oui - Essai de recherche
-
Il s'agit de l'opération de « recherche » LDAP , et sera utilisée pour définir des recherches.
Paramètres
AttributLa descriptionObligatoireNomNom descriptif de cet échantillonneur affiché dans l'arborescence.NonBase de rechercheNom distinctif de la sous-arborescence dans laquelle vous souhaitez que votre recherche porte, par rapport au DN donné dans l'opération de liaison de thread.NonFiltre de recherchesearchfilter, doit être spécifié dans la syntaxe LDAP.OuiPortéeUtilisez 0 pour baseobject-, 1 pour onelevel- et 2 pour une recherche de sous-arborescence. (Par défaut= 0 )NonLimite de tailleSpécifiez le nombre maximum de résultats que vous souhaitez obtenir du serveur. (par défaut = 0 , ce qui signifie qu'il n'y a pas de limite.) Lorsque l'échantillonneur atteint le nombre maximum de résultats, il échoue avec le code d'erreur 4NonLimite de tempsSpécifiez le temps (cpu) maximal (en millisecondes) que le serveur peut consacrer à votre recherche. Attention, cela ne dit rien sur le temps de réponse. (la valeur par défaut est 0 , ce qui signifie qu'il n'y a pas de limite)NonLes attributsSpécifiez les attributs que vous souhaitez renvoyer, séparés par un point-virgule. Un champ vide renverra tous les attributsNonObjet de retourIndique si l'objet sera renvoyé ( true ) ou non ( false ). Par défaut = fauxNonDéréférencer les aliasSi true , il déréférencera les alias, si false , il ne les suivra pas (default= false )NonAnalyser les résultats de la recherche ?Si true , les résultats de la recherche seront ajoutés aux données de réponse. Si false , un marqueur - que les résultats aient été trouvés ou non - sera ajouté aux données de réponse.Non - Essai de modifications
-
Il s'agit de l'opération " modifier " LDAP . Il peut être utilisé pour modifier un objet. Il peut être utilisé pour ajouter, supprimer ou remplacer les valeurs d'un attribut.
Paramètres
AttributLa descriptionObligatoireNomNom descriptif de cet échantillonneur affiché dans l'arborescence.NonNom de l'entréeNom distinctif de l'objet que vous souhaitez modifier, par rapport au DN donné dans l'opération de liaison de threadOuiEssai de modificationsL'attribut-valeur-opCode triple.
L' opCode peut être n'importe quel code d'opération LDAP valide ( add , delete , remove ou replace ).
Si vous ne spécifiez pas de valeur avec une opération de suppression , toutes les valeurs de l'attribut donné seront supprimées.
Si vous spécifiez une valeur dans une opération de suppression , seule la valeur donnée sera supprimée.
Si cette valeur est inexistante, l'échantillonneur échouera au test.Oui - Comparer
-
Il s'agit de l'opération " comparer " LDAP . Il peut être utilisé pour comparer la valeur d'un attribut donné avec une valeur déjà connue. En réalité, cela est principalement utilisé pour vérifier si une personne donnée est membre d'un groupe. Dans un tel cas, vous pouvez comparer le DN de l'utilisateur en tant que valeur donnée, avec les valeurs de l'attribut « membre » d'un objet de type groupOfNames . Si l'opération de comparaison échoue, ce test échoue avec le code d'erreur 49 .
Paramètres
AttributLa descriptionObligatoireNomNom descriptif de cet échantillonneur affiché dans l'arborescence.NonDN d'entréeLe nom distinctif actuel de l'objet dont vous souhaitez comparer un attribut, par rapport au DN donné dans l'opération de liaison de thread.OuiComparer le filtreSous la forme " attribut=valeur "Oui
Accéder à l'échantillonneur de journaux ¶
AccessLogSampler a été conçu pour lire les journaux d'accès et générer des requêtes http. Pour ceux qui ne connaissent pas le journal d'accès, il s'agit du journal que le serveur Web conserve pour chaque demande acceptée. Cela signifie que chaque image, fichier CSS, fichier JavaScript, fichier html, …
Tomcat utilise le format commun pour les journaux d'accès. Cela signifie que tout serveur Web qui utilise le format de journal commun peut utiliser AccessLogSampler. Les serveurs qui utilisent le format de journal commun incluent : Tomcat, Resin, Weblogic et SunOne. Le format de journal courant ressemble à ceci :
127.0.0.1 - - [21/Oct/2003:05:37:21 -0500] "GET /index.jsp?%2Findex.jsp= HTTP/1.1" 200 8343
À l'avenir, il pourrait être utile de filtrer les entrées qui n'ont pas de code de réponse 200 . L'extension de l'échantillonneur devrait être assez simple. Il y a deux interfaces que vous devez implémenter :
- org.apache.jmeter.protocol.http.util.accesslog.LogParser
- org.apache.jmeter.protocol.http.util.accesslog.Generator
L'implémentation actuelle d'AccessLogSampler utilise le générateur pour créer un nouveau HTTPSampler. Le nom du serveur, le port et les images get sont définis par AccessLogSampler. Ensuite, l'analyseur est appelé avec l'entier 1 , lui indiquant d'analyser une entrée. Après cela, HTTPSampler.sample() est appelé pour effectuer la requête.
samp = (HTTPSampler) GENERATOR.generateRequest(); samp.setDomain(this.getDomain()); samp.setPort(this.getPort()); samp.setImageParser(this.isImageParser()); PARSER.parse(1); res = samp.sample(); res.setSampleLabel(samp.toString());Les méthodes requises dans LogParser sont :
- setGenerator(Générateur)
- analyser (entier)
Les classes implémentant l'interface Generator doivent fournir une implémentation concrète pour toutes les méthodes. Pour un exemple d'implémentation de l'une ou l'autre interface, reportez-vous à StandardGenerator et TCLogParser .

(Code bêta)
Paramètres ¶
Le TCLogParser traite le journal d'accès indépendamment pour chaque thread. SharedTCLogParser et OrderPreservingLogParser partagent l' accès au fichier, c'est-à-dire que chaque thread obtient l'entrée suivante dans le journal.
Le SessionFilter est destiné à gérer les cookies à travers les threads. Il ne filtre aucune entrée, mais modifie le gestionnaire de cookies afin que les cookies d'une adresse IP donnée soient traités par un seul thread à la fois. Si deux threads tentent de traiter des échantillons à partir de la même adresse IP client, l'un sera obligé d'attendre que l'autre ait terminé.
Le LogFilter est destiné à permettre aux entrées du journal d'accès d'être filtrées par nom de fichier et regex, ainsi qu'au remplacement des extensions de fichier. Cependant, il n'est actuellement pas possible de le configurer via l'interface graphique, il ne peut donc pas vraiment être utilisé.
Échantillonneur BeanShell ¶
Cet échantillonneur vous permet d'écrire un échantillonneur à l'aide du langage de script BeanShell.
Pour plus de détails sur l'utilisation de BeanShell, veuillez consulter le site Web de BeanShell.
L'élément de test prend en charge les méthodes d'interface ThreadListener et TestListener . Ceux-ci doivent être définis dans le fichier d'initialisation. Voir le fichier BeanShellListeners.bshrc pour des exemples de définitions.
L'échantillonneur BeanShell prend également en charge l' interface Interruptible . La méthode interrupt() peut être définie dans le script ou le fichier init.

Paramètres ¶
- Paramètres
- chaîne contenant les paramètres comme une seule variable
- bsh.args
- Tableau de chaînes contenant des paramètres, divisés en espaces blancs
Si la propriété " beanshell.sampler.init " est définie, elle est transmise à l'interpréteur en tant que nom d'un fichier sourcé. Cela peut être utilisé pour définir des méthodes et des variables communes. Il existe un exemple de fichier init dans le répertoire bin : BeanShellSampler.bshrc .
Si un fichier de script est fourni, il sera utilisé, sinon le script sera utilisé.
BeanShell ne prend actuellement pas en charge la syntaxe Java 5 telle que les génériques et la boucle for améliorée.
Avant d'invoquer le script, certaines variables sont configurées dans l'interpréteur BeanShell :
Le contenu du champ Paramètres est placé dans la variable « Paramètres ». La chaîne est également divisée en jetons séparés en utilisant un seul espace comme séparateur, et la liste résultante est stockée dans le tableau String bsh.args .
La liste complète des variables BeanShell configurées est la suivante :
- log - l' enregistreur
- Étiquette - l'étiquette Sampler
- FileName - le nom du fichier, le cas échéant
- Paramètres - texte du champ Paramètres
- bsh.args - les paramètres, divisés comme décrit ci-dessus
- SampleResult - pointeur vers le SampleResult actuel
- ResponseCode par défaut est 200
- ResponseMessage est par défaut " OK "
- IsSuccess est vrai par défaut
- ctx - JMeterContext
-
vars - JMeterVariables - par exemple
vars.get("VAR1"); vars.put("VAR2","valeur"); vars.remove("VAR3"); vars.putObject("OBJ1",nouvel objet()); -
accessoires - JMeterProperties (classe java.util.Properties ) - par exemple
props.get("START.HMS"); props.put("PROP1","1234");
Une fois le script terminé, le contrôle est rendu à Sampler et il copie le contenu des variables de script suivantes dans les variables correspondantes de SampleResult :
- ResponseCode - par exemple 200
- ResponseMessage - par exemple " OK "
- IsSuccess - vrai ou faux
Le SampleResult ResponseData est défini à partir de la valeur de retour du script. Si le script renvoie null, il peut définir la réponse directement, en utilisant la méthode SampleResult.setResponseData(data) , où data est soit une chaîne, soit un tableau d'octets. Le type de données par défaut est " text ", mais peut être défini sur binaire à l'aide de la méthode SampleResult.setDataType(SampleResult.BINARY) .
La variable SampleResult donne au script un accès complet à tous les champs et méthodes de SampleResult . Par exemple, le script a accès aux méthodes setStopThread(boolean) et setStopTest(boolean) . Voici un exemple de script simple (pas très utile !) :
if (bsh.args[0].equalsIgnoreCase("StopThread")) {
log.info("Arrêter le thread détecté !");
SampleResult.setStopThread(true);
}
return "Données de l'échantillon avec Label "+Label ;
//ou
SampleResult.setResponseData("Mes données");
renvoie nul ;
Autre exemple :
assurez-vous que la propriété beanshell.sampler.init=BeanShellSampler.bshrc est définie dans jmeter.properties . Le script suivant affichera les valeurs de toutes les variables dans le champ ResponseData :
retourne getVariables();
Pour plus de détails sur les méthodes disponibles pour les différentes classes ( JMeterVariables , SampleResult etc.), veuillez consulter la Javadoc ou le code source. Méfiez-vous cependant que l'utilisation abusive de toute méthode peut entraîner des défauts subtils qui peuvent être difficiles à trouver.
Échantillonneur JSR223 ¶
L'échantillonneur JSR223 permet d'utiliser le code de script JSR223 pour effectuer un échantillon ou un calcul requis pour créer/mettre à jour des variables.
SampleResult.setIgnore();Cet appel aura l'impact suivant :
- SampleResult ne sera pas livré aux SampleListeners comme View Results Tree, Summariser ...
- SampleResult ne sera pas évalué dans Assertions ni PostProcessors
- SampleResult sera évalué pour calculer l'état du dernier échantillon (${JMeterThread.last_sample_ok}) et ThreadGroup "Action à entreprendre après une erreur Sampler" (depuis JMeter 5.4)
Les éléments de test JSR223 ont une fonctionnalité (compilation) qui peut augmenter considérablement les performances. Pour bénéficier de cette fonctionnalité :
- Utilisez des fichiers de script au lieu de les intégrer. Cela obligera JMeter à les compiler si cette fonctionnalité est disponible sur ScriptEngine et à les mettre en cache.
- Ou utilisez le texte du script et cochez la propriété Script compilé en cache si disponible .
Lorsque vous utilisez cette fonctionnalité, assurez-vous que votre code de script n'utilise pas de variables JMeter ou d'appels de fonction JMeter directement dans le code de script, car la mise en cache ne mettrait en cache que le premier remplacement. Utilisez plutôt des paramètres de script.Pour bénéficier de la mise en cache et de la compilation, le moteur de langage utilisé pour les scripts doit implémenter l' interface compilable JSR223 (Groovy en fait partie, java, beanshell et javascript ne le sont pas)Lorsque vous utilisez Groovy comme langage de script et que vous ne cochez pas le script compilé du cache s'il est disponible (alors que la mise en cache est recommandée), vous devez définir cette propriété JVM -Dgroovy.use.classvalue=true en raison d'une fuite de mémoire Groovy à partir de la version 2.4.6, voir :
jsr223.compiled_scripts_cache_size=100

props.get("START.HMS");
props.put("PROP1","1234");
Paramètres ¶
Notez que certains langages tels que Velocity peuvent utiliser une syntaxe différente pour les variables JSR223, par exemple
$log.debug("Bonjour " + $vars.get("a"));pour la vitesse.
Si un fichier de script est fourni, il sera utilisé, sinon le script sera utilisé.
Avant d'invoquer le script, certaines variables sont configurées. Notez qu'il s'agit de variables JSR223 - c'est-à-dire qu'elles peuvent être utilisées directement dans le script.
- log - l' enregistreur
- Étiquette - l'étiquette Sampler
- FileName - le nom du fichier, le cas échéant
- Paramètres - texte du champ Paramètres
- args - les paramètres, divisés comme décrit ci-dessus
- SampleResult - pointeur vers le SampleResult actuel
- sampler - ( Sampler ) - pointeur vers l'échantillonneur actuel
- ctx - JMeterContext
-
vars - JMeterVariables - par exemple
vars.get("VAR1"); vars.put("VAR2","valeur"); vars.remove("VAR3"); vars.putObject("OBJ1",nouvel objet()); -
accessoires - JMeterProperties (classe java.util.Properties ) - par exemple
props.get("START.HMS"); props.put("PROP1","1234"); - OUT - System.out - par exemple OUT.println("message")
Le SampleResult ResponseData est défini à partir de la valeur de retour du script. Si le script renvoie null , il peut définir la réponse directement, en utilisant la méthode SampleResult.setResponseData(data) , où data est soit une chaîne soit un tableau d'octets. Le type de données par défaut est " text ", mais peut être défini sur binaire à l'aide de la méthode SampleResult.setDataType(SampleResult.BINARY) .
La variable SampleResult donne au script un accès complet à tous les champs et méthodes de SampleResult. Par exemple, le script a accès aux méthodes setStopThread(boolean) et setStopTest(boolean) .
Contrairement à l'échantillonneur BeanShell, l'échantillonneur JSR223 ne définit pas le ResponseCode , le ResponseMessage et l'état de l'échantillon via des variables de script. Actuellement, le seul moyen de les modifier est via les méthodes SampleResult :
- SampleResult.setSuccessful(true/false)
- SampleResult.setResponseCode("code")
- SampleResult.setResponseMessage("message")
Échantillonneur TCP ¶
L'échantillonneur TCP ouvre une connexion TCP/IP au serveur spécifié. Il envoie ensuite le texte et attend une réponse.
Si « Réutiliser la connexion » est sélectionné, les connexions sont partagées entre les échantillonneurs dans le même thread, à condition que la même chaîne de nom d'hôte et le même port soient utilisés. Différentes combinaisons hôtes/ports utiliseront différentes connexions, tout comme différents threads. Si " Réutiliser la connexion " et " Fermer la connexion " sont tous les deux sélectionnés, la prise sera fermée après l'exécution de l'échantillonneur. Sur le sampler suivant, un autre socket sera créé. Vous voudrez peut-être fermer un socket à la fin de chaque boucle de thread.
Si une erreur est détectée - ou " Réutiliser la connexion " n'est pas sélectionné - le socket est fermé. Une autre prise sera rouverte sur le prochain échantillon.
Les propriétés suivantes peuvent être utilisées pour contrôler son fonctionnement :
- tcp.status.prefix
- texte qui précède un numéro d'état
- tcp.status.suffix
- texte qui suit un numéro d'état
- tcp.status.properties
- nom du fichier de propriétés pour convertir les codes d'état en messages
- tcp.handler
- Nom de la classe TCP Handler (par défaut TCPClientImpl ) - utilisé uniquement s'il n'est pas spécifié sur l'interface graphique
Les utilisateurs peuvent fournir leur propre implémentation. La classe doit étendre org.apache.jmeter.protocol.tcp.sampler.TCPClient .
Les implémentations suivantes sont actuellement fournies.
- TCPClientImpl
- BinaryTCPCClientImpl
- LengthPrefixedBinaryTCPClientImpl
- TCPClientImpl
- Cette implémentation est assez basique. Lors de la lecture de la réponse, il lit jusqu'à l'octet de fin de ligne, si cela est défini en définissant la propriété tcp.eolByte , sinon jusqu'à la fin du flux d'entrée. Vous pouvez contrôler l'encodage du jeu de caractères en définissant tcp.charset , qui sera par défaut l'encodage par défaut de la plate-forme.
- BinaryTCPCClientImpl
- Cette implémentation convertit l'entrée de l'interface graphique, qui doit être une chaîne codée en hexadécimal, en binaire, et effectue l'inverse lors de la lecture de la réponse. Lors de la lecture de la réponse, il lit jusqu'à la fin de l'octet de message, si cela est défini en définissant la propriété tcp.BinaryTCPClient.eomByte , sinon jusqu'à la fin du flux d'entrée.
- LengthPrefixedBinaryTCPClientImpl
- Cette implémentation étend BinaryTCPClientImpl en préfixant les données du message binaire avec un octet de longueur binaire. Le préfixe de longueur par défaut est de 2 octets. Cela peut être modifié en définissant la propriété tcp.binarylength.prefix.length .
- Gestion du délai d'attente
- Si le délai d'attente est défini, la lecture sera terminée à son expiration. Donc, si vous utilisez un eolByte / eomByte , assurez-vous que le délai d'attente est suffisamment long, sinon la lecture sera terminée plus tôt.
- Gestion des réponses
-
Si tcp.status.prefix est défini, le message de réponse est recherché pour le texte suivant jusqu'au suffixe. Si un tel texte est trouvé, il est utilisé pour définir le code de réponse. Le message de réponse est ensuite extrait du fichier de propriétés (s'il est fourni).
Les codes de réponse dans la plage " 400 "-" 499 " et " 500 "-" 599 " sont actuellement considérés comme des échecs ; tous les autres réussissent. [Cela doit être rendu configurable !]Utilisation du pré- et du suffixe ¶Par exemple, si le préfixe = " [ " et le suffixe = " ] ", alors la réponse suivante :
[J28] XI123,23,GBP,CR
aurait le code de réponse J28 .
Les prises sont déconnectées à la fin d'un test.

Paramètres ¶
Éditeur JMS ¶
JMS Publisher publiera les messages vers une destination donnée (sujet/file d'attente). Pour ceux qui ne connaissent pas JMS, il s'agit de la spécification J2EE pour la messagerie. Il existe de nombreux serveurs JMS sur le marché et plusieurs options open source.

Paramètres ¶
- À partir du fichier
- signifie que le fichier référencé sera lu et réutilisé par tous les échantillons. Si le nom du fichier change, il est rechargé depuis JMeter 3.0
- Fichier aléatoire du dossier spécifié ci-dessous
- signifie qu'un fichier aléatoire sera sélectionné dans le dossier spécifié ci-dessous, ce dossier doit contenir soit des fichiers avec l'extension .dat pour les messages Bytes, soit des fichiers avec l'extension .txt ou .obj pour les messages Object ou Text
- Zone de texte
- Le message à utiliser pour le message texte ou objet
- BRUT :
- Pas de prise en charge des variables à partir du fichier et chargez-le avec le jeu de caractères système par défaut.
- PAR DÉFAUT :
- Charger le fichier avec l'encodage système par défaut, à l'exception de XML qui repose sur le prologue XML. Si le fichier contient des variables, elles seront traitées.
- Jeux de caractères standard :
- L'encodage spécifié (valide ou non) est utilisé pour la lecture du fichier et le traitement des variables
Pour le type MapMessage, JMeter lit la source sous forme de lignes de texte. Chaque ligne doit comporter 3 champs, délimités par des virgules. Les champs sont :
- Nom de l'entrée
- Nom de classe d'objet, par exemple " String " (suppose le package java.lang s'il n'est pas spécifié)
- Valeur de chaîne d'objet
nom, chaîne, exemple taille,Entier,1234
- Mettez le JAR qui contient votre objet et ses dépendances dans le dossier jmeter_home/lib/
- Sérialisez votre objet en XML à l'aide de XStream
- Mettez le résultat dans un fichier suffixé par .txt ou .obj ou placez le contenu XML directement dans la zone de texte
Le tableau suivant montre quelques valeurs qui peuvent être utiles lors de la configuration de JMS :
| Apache ActiveMQ | Valeurs) | Commentaire |
|---|---|---|
| Usine de contexte | org.apache.activemq.jndi.ActiveMQInitialContextFactory | . |
| URL du fournisseur | vm://localhost | |
| URL du fournisseur | machine virtuelle :(broker :(vm://localhost)?persistent=false) | Désactiver la persistance |
| Référence de file d'attente | files d'attente dynamiques/NOM DE LA FILE | Définir dynamiquement le QUEUENAME à JNDI |
| Référence de rubrique | Sujets dynamiques/NOM DU SUJET | Définir dynamiquement le TOPICNAME à JNDI |
Abonné JMS ¶
L'abonné JMS s'abonnera aux messages d'une destination donnée (sujet ou file d'attente). Pour ceux qui ne connaissent pas JMS, il s'agit de la spécification J2EE pour la messagerie. Il existe de nombreux serveurs JMS sur le marché et plusieurs options open source.

Paramètres ¶
- MessageConsumer.receive()
- appelle receive() pour chaque message demandé. Conserve la connexion entre les échantillons, mais ne récupère pas les messages à moins que l'échantillonneur ne soit actif. Ceci est mieux adapté aux abonnements à la file d'attente.
- MessageListener.onMessage()
- établit un écouteur qui stocke tous les messages entrants dans une file d'attente. L'écouteur reste actif une fois l'échantillonneur terminé. Ceci est mieux adapté aux abonnements Topic.
Point à point JMS ¶
Cet échantillonneur envoie et reçoit éventuellement des messages JMS via des connexions point à point (files d'attente). Il est différent des messages pub/sub et est généralement utilisé pour gérer les transactions.
request_only sera généralement utilisé pour charger un système JMS.
request_reply sera utilisé lorsque vous souhaitez tester le temps de réponse d'un service JMS qui traite les messages envoyés à la file d'attente des demandes car ce mode attendra la réponse sur la file d'attente des réponses envoyée par ce service.
parcourir renvoie la profondeur actuelle de la file d'attente, c'est-à-dire le nombre de messages dans la file d'attente.
read lit un message de la file d'attente (le cas échéant).
clear vide la file d'attente, c'est-à-dire supprime tous les messages de la file d'attente.
JMeter utilise les propriétés java.naming.security.[principal|credentials] - si elles sont présentes - lors de la création de la connexion à la file d'attente. Si ce comportement n'est pas souhaité, définissez la propriété JMeter JMSSampler.useSecurity.properties=false

Paramètres ¶
- Demande uniquement
- n'enverra que des messages et ne surveillera pas les réponses. En tant que tel, il peut être utilisé pour charger un système.
- Demande de réponse
- enverra des messages et surveillera les réponses qu'il reçoit. Le comportement dépend de la valeur de la file d'attente de réponse de nom JNDI. Si JNDI Name Reply Queue a une valeur, cette file d'attente est utilisée pour surveiller les résultats. La correspondance de la demande et de la réponse est effectuée avec l'ID de message de la demande et l'ID de corrélation de la réponse. Si la file d'attente de réponse de nom JNDI est vide, des files d'attente temporaires seront utilisées pour la communication entre le demandeur et le serveur. Ceci est très différent de la file d'attente de réponse fixe. Avec les files d'attente temporaires, le thread d'envoi sera bloqué jusqu'à ce que le message de réponse ait été reçu. Avec le mode Request Response , vous devez disposer d'un serveur qui écoute les messages envoyés à Request Queue et envoie des réponses à la file d'attente référencée par message.getJMSReplyTo() .
- Lis
- lira un message d'une file d'attente sortante qui n'a aucun écouteur attaché. Cela peut être pratique à des fins de test. Cette méthode peut être utilisée si vous avez besoin de gérer des files d'attente sans fichier de liaison (au cas où la bibliothèque jmeter-jms-skip-jndi est utilisée), qui ne fonctionne qu'avec l'échantillonneur JMS Point-to-Point. Dans le cas où des fichiers de liaison sont utilisés, on peut également utiliser l'échantillonneur d'abonnés JMS pour lire à partir d'une file d'attente.
- Parcourir
- déterminera la profondeur actuelle de la file d'attente sans supprimer les messages de la file d'attente, renvoyant le nombre de messages dans la file d'attente.
- Dégager
- effacera la file d'attente, c'est-à-dire supprimera tous les messages de la file d'attente.
- Utiliser l'identifiant du message de demande
- si sélectionné, la requête JMSMessageID sera utilisée, sinon la requête JMSCorrelationID sera utilisée. Dans ce dernier cas, l'identifiant de corrélation doit être spécifié dans la requête.
- Utiliser l'identifiant du message de réponse
- si sélectionné, la réponse JMSMessageID sera utilisée, sinon la réponse JMSCorrelationID sera utilisée.
- Modèle d'ID de corrélation JMS
- c'est-à-dire faire correspondre la demande et la réponse sur leurs identifiants de corrélation => décochez les deux cases et fournissez un identifiant de corrélation.
- Modèle d'ID de message JMS
- c'est-à-dire faire correspondre l'identifiant du message de requête avec l'identifiant de corrélation de réponse => sélectionnez "Utiliser l'identifiant de message de requête" uniquement.
Requête JUnit ¶
- plutôt que d'utiliser l'interface de test de JMeter, il analyse les fichiers jar pour les classes étendant la classe TestCase de JUnit . Cela inclut toute classe ou sous-classe.
- Les fichiers jar de test JUnit doivent être placés dans jmeter/lib/junit au lieu du répertoire /lib . Vous pouvez également utiliser la propriété " user.classpath " pour spécifier où chercher les classes TestCase .
- L'échantillonneur JUnit n'utilise pas de paires nom/valeur pour la configuration comme Java Request . L'échantillonneur suppose que setUp et tearDown configureront le test correctement.
- L'échantillonneur mesure le temps écoulé uniquement pour la méthode de test et n'inclut pas setUp et tearDown .
- Chaque fois que la méthode de test est appelée, JMeter transmettra le résultat aux écouteurs.
- La prise en charge de oneTimeSetUp et oneTimeTearDown se fait en tant que méthode. Étant donné que JMeter est multi-thread, nous ne pouvons pas appeler oneTimeSetUp / oneTimeTearDown de la même manière que Maven le fait.
- L'échantillonneur signale les exceptions inattendues comme des erreurs. Il existe des différences importantes entre les exécuteurs de test JUnit standard et l'implémentation de JMeter. Plutôt que de créer une nouvelle instance de la classe pour chaque test, JMeter crée 1 instance par échantillonneur et la réutilise. Cela peut être changé avec la case à cocher " Créer une nouvelle instance par échantillon ".
public class myTestCase {
public myTestCase() {}
}
Constructeur de chaînes :
public class myTestCase {
public myTestCase(String text) {
super(texte);
}
}
Conditions générales d'Utilisation
Si vous utilisez setUp et tearDown , assurez-vous que les méthodes sont déclarées publiques. Si vous ne le faites pas, le test risque de ne pas s'exécuter correctement.Voici quelques directives générales pour écrire des tests JUnit afin qu'ils fonctionnent bien avec JMeter. Étant donné que JMeter fonctionne en multithread, il est important de garder certaines choses à l'esprit.
- Écrivez les méthodes setUp et tearDown afin qu'elles soient thread-safe. Cela signifie généralement éviter d'utiliser des membres statiques.
- Faites en sorte que les méthodes de test soient des unités de travail discrètes et non de longues séquences d'actions. En gardant la méthode de test à une opération discrète, il est plus facile de combiner des méthodes de test pour créer de nouveaux plans de test.
- Évitez de faire dépendre les méthodes de test les unes des autres. Étant donné que JMeter permet le séquençage arbitraire des méthodes de test, le comportement d'exécution est différent du comportement par défaut de JUnit.
- Si une méthode de test est configurable, faites attention à l'endroit où les propriétés sont stockées. Il est recommandé de lire les propriétés du fichier Jar.
- Chaque échantillonneur crée une instance de la classe de test, alors écrivez votre test pour que la configuration se fasse dans oneTimeSetUp et oneTimeTearDown .

Paramètres ¶
Les annotations JUnit4 suivantes sont reconnues :
- @Test
- utilisé pour trouver des méthodes de test et des classes. Les attributs " attendu " et " timeout " sont supportés.
- @Avant de
- traité de la même manière que setUp() dans JUnit3
- @Après
- traité de la même manière que tearDown() dans JUnit3
- @AvantClasse , @AprèsClasse
- traités comme des méthodes de test afin qu'ils puissent être exécutés indépendamment selon les besoins
Échantillonneur de lecteur de courrier ¶
L'échantillonneur de lecteur de courrier peut lire (et éventuellement supprimer) des messages électroniques à l'aide des protocoles POP3(S) ou IMAP(S).

Paramètres ¶
A défaut, contre le répertoire contenant le script de test (fichier JMX).
Les messages sont stockés en tant que sous-échantillons de l'échantillonneur principal. Les parties de message en plusieurs parties sont stockées en tant que sous-échantillons du message.
Traitement spécial pour le protocole " file
" :
Le fournisseur de fichiers JavaMail peut être utilisé pour lire des messages bruts à partir de fichiers. Le champ serveur est utilisé pour spécifier le chemin d'accès au parent du dossier . Les fichiers de messages individuels doivent être stockés avec le nom n.msg , où n est le numéro du message. Alternativement, le champ du serveur peut être le nom d'un fichier qui contient un seul message. L'implémentation actuelle est assez basique et est principalement destinée à des fins de débogage.
Action de contrôle de flux (auparavant : Action de test ) ¶
Cet échantillonneur peut également être utile en conjonction avec le contrôleur de transaction, car il permet d'inclure des pauses sans avoir besoin de générer un échantillon. Pour les retards variables, réglez le temps de pause sur zéro et ajoutez un minuteur en tant qu'enfant.
L'action " Arrêter " arrête le thread ou le test après avoir terminé tous les échantillons en cours. L'action « Arrêter maintenant » arrête le test sans attendre que les échantillons soient terminés ; cela interrompra tous les échantillons actifs. Si certains threads ne s'arrêtent pas dans le délai de 5 secondes, un message s'affichera en mode GUI. Vous pouvez essayer d'utiliser la commande Stop pour voir si cela arrêtera les threads, mais si ce n'est pas le cas, vous devez quitter JMeter. En mode CLI, JMeter se fermera si certains threads ne s'arrêtent pas dans le délai de 5 secondes.

Paramètres ¶
Échantillonneur SMTP ¶
L'échantillonneur SMTP peut envoyer des messages électroniques à l'aide du protocole SMTP/SMTPS. Il est possible de définir des protocoles de sécurité pour la connexion (SSL et TLS), ainsi que l'authentification des utilisateurs. Si un protocole de sécurité est utilisé, une vérification sur le certificat du serveur aura lieu.
Deux alternatives pour gérer cette vérification sont disponibles :
- Faire confiance à tous les certificats
- Cela ignorera la vérification de la chaîne de certificats
- Utiliser un truststore local
- Avec cette option, la chaîne de certificats sera validée par rapport au fichier truststore local.

Paramètres ¶
A défaut, contre le répertoire contenant le script de test (fichier JMX).
Échantillonneur de processus de système d'exploitation ¶
L'échantillonneur de processus du système d'exploitation est un échantillonneur qui peut être utilisé pour exécuter des commandes sur la machine locale.
Il devrait permettre l'exécution de toute commande pouvant être exécutée à partir de la ligne de commande.
La validation du code de retour peut être activée et le code de retour attendu peut être spécifié.
Notez que les shells du système d'exploitation fournissent généralement une analyse de ligne de commande. Cela varie d'un système d'exploitation à l'autre, mais généralement, le shell divisera les paramètres sur l'espace blanc. Certains shells étendent les noms de fichiers génériques ; certains ne le font pas. Le mécanisme de citation varie également entre les systèmes d'exploitation. L'échantillonneur ne fait délibérément aucune analyse ou gestion des citations. La commande et ses paramètres doivent être fournis sous la forme attendue par l'exécutable. Cela signifie que les paramètres de l'échantillonneur ne seront pas portables entre les systèmes d'exploitation.
De nombreux systèmes d'exploitation ont des commandes intégrées qui ne sont pas fournies en tant qu'exécutables séparés. Par exemple, la commande Windows DIR fait partie de l'interpréteur de commandes ( CMD.EXE ). Ces éléments intégrés ne peuvent pas être exécutés en tant que programmes indépendants, mais doivent être fournis en tant qu'arguments à l'interpréteur de commandes approprié.
Par exemple, la ligne de commande Windows : DIR C:\TEMP doit être spécifiée comme suit :
- Commande:
- CMD
- Paramètre 1 :
- /C
- Paramètre 2 :
- REP
- Paramètre 3 :
- C:\TEMP

Paramètres ¶
Script MongoDB (OBSOLETE) ¶
Cet échantillonneur vous permet d'envoyer une requête à une MongoDB.
Avant de l'utiliser, vous devez configurer un élément MongoDB Source Config Configuration

Paramètres ¶
Requête de boulon ¶
Cet échantillonneur vous permet d'exécuter des requêtes Cypher via le protocole Bolt.
Avant de l'utiliser, vous devez configurer une configuration de connexion par boulon
Chaque demande utilise une connexion acquise à partir du pool et la renvoie au pool lorsque l'échantillonneur se termine. La taille du pool de connexion utilise les valeurs par défaut du pilote (~100) et n'est pas configurable pour le moment.
Le temps de réponse mesuré correspond à l'exécution "complète" de la requête, comprenant à la fois le temps d'exécution de la requête de chiffrement ET le temps de consommation des résultats renvoyés par la base de données.

Paramètres ¶
18.2 Contrôleurs logiques ¶
Les contrôleurs logiques déterminent l'ordre dans lequel les échantillonneurs sont traités.
Contrôleur simple ¶
Le contrôleur logique simple vous permet d'organiser vos échantillonneurs et autres contrôleurs logiques. Contrairement aux autres contrôleurs logiques, ce contrôleur ne fournit aucune fonctionnalité au-delà de celle d'un périphérique de stockage.

Paramètres ¶
Téléchargez cet exemple (voir Figure 6). Dans cet exemple, nous avons créé un plan de test qui envoie deux requêtes HTTP Ant et deux requêtes HTTP Log4J. Nous avons regroupé les requêtes Ant et Log4J en les plaçant dans des contrôleurs logiques simples. N'oubliez pas que le contrôleur logique simple n'a aucun effet sur la façon dont JMeter traite le ou les contrôleurs que vous y ajoutez. Ainsi, dans cet exemple, JMeter envoie les requêtes dans l'ordre suivant : Ant Home Page, Ant News Page, Log4J Home Page, Log4J History Page.
A noter, le File Reporter est configuré pour stocker les résultats dans un fichier nommé " simple-test.dat " dans le répertoire courant.

Contrôleur de boucle ¶
Si vous ajoutez des contrôleurs génératifs ou logiques à un contrôleur de boucle, JMeter les parcourra un certain nombre de fois, en plus de la valeur de boucle que vous avez spécifiée pour le groupe de threads. Par exemple, si vous ajoutez une requête HTTP à un contrôleur de boucle avec un nombre de boucles de deux et que vous configurez le nombre de boucles du groupe de threads sur trois, JMeter enverra un total de 2 * 3 = 6 requêtes HTTP.

Paramètres ¶
La valeur -1 équivaut à cocher la bascule Forever .
Cas particulier : le contrôleur de boucle intégré dans l' élément Groupe de threads se comporte légèrement différemment. À moins qu'il ne soit défini sur pour toujours, il arrête le test après que le nombre donné d'itérations ait été effectué.
Téléchargez cet exemple (voir Figure 4). Dans cet exemple, nous avons créé un plan de test qui envoie une seule requête HTTP particulière et envoie cinq fois une autre requête HTTP.

Nous avons configuré le groupe de threads pour un seul thread et une valeur de nombre de boucles de un. Au lieu de laisser le groupe de threads contrôler la boucle, nous avons utilisé un contrôleur de boucle. Vous pouvez voir que nous avons ajouté une requête HTTP au groupe de threads et une autre requête HTTP à un contrôleur de boucle. Nous avons configuré le contrôleur de boucle avec une valeur de nombre de boucles de cinq.
JMeter enverra les demandes dans l'ordre suivant : page d'accueil, page d'actualités, page d'actualités, page d'actualités, page d'actualités et page d'actualités.
Contrôleur unique ¶
Le contrôleur logique unique indique à JMeter de traiter le ou les contrôleurs à l'intérieur une seule fois par thread et de transmettre toutes les requêtes sous celui-ci lors d'itérations ultérieures dans le plan de test.
Le contrôleur Once Only s'exécutera désormais toujours lors de la première itération de tout contrôleur parent en boucle. Ainsi, si le contrôleur unique est placé sous un contrôleur de boucle spécifié pour boucler 5 fois, le contrôleur unique ne s'exécutera qu'à la première itération via le contrôleur de boucle (c'est-à-dire toutes les 5 fois).
Notez que cela signifie que le contrôleur Once Only se comportera toujours comme prévu s'il est placé dans un groupe de threads (s'exécute une seule fois par test et par thread), mais l'utilisateur dispose désormais d'une plus grande flexibilité dans l'utilisation du contrôleur Once Only.
Pour les tests nécessitant une connexion, envisagez de placer la demande de connexion dans ce contrôleur, car chaque thread n'a besoin de se connecter qu'une seule fois pour établir une session.

Paramètres ¶
Téléchargez cet exemple (voir Figure 5). Dans cet exemple, nous avons créé un plan de test qui comporte deux threads qui envoient une requête HTTP. Chaque thread envoie une requête à la page d'accueil, suivie de trois requêtes à la page de bogue. Bien que nous ayons configuré le groupe de threads pour itérer trois fois, chaque thread JMeter n'envoie qu'une seule requête à la page d'accueil car cette requête réside dans un contrôleur unique.

Chaque thread JMeter enverra les requêtes dans l'ordre suivant : page d'accueil, page de bogue, page de bogue, page de bogue.
Notez que le File Reporter est configuré pour stocker les résultats dans un fichier nommé " loop-test.dat " dans le répertoire courant.
Contrôleur d'entrelacement ¶
Si vous ajoutez des contrôleurs génératifs ou logiques à un contrôleur entrelacé, JMeter alternera entre chacun des autres contrôleurs pour chaque itération de boucle.

Paramètres ¶
Téléchargez cet exemple (voir Figure 1). Dans cet exemple, nous avons configuré le groupe de threads pour avoir deux threads et un nombre de boucles de cinq, pour un total de dix requêtes par thread. Voir le tableau ci-dessous pour la séquence JMeter envoie les requêtes HTTP.

| Itération de boucle | Chaque thread JMeter envoie ces requêtes HTTP |
|---|---|
| 1 | Actualités |
| 1 | Page du journal |
| 2 | FAQ |
| 2 | Page du journal |
| 3 | Page Gump |
| 3 | Page du journal |
| 4 | Comme il n'y a plus de requêtes dans le contrôleur, JMeter recommence et envoie la première requête HTTP, qui est la page d'actualités. |
| 4 | Page du journal |
| 5 | FAQ |
| 5 | Page du journal |
Téléchargez un autre exemple (voir Figure 2). Dans cet exemple, nous avons configuré le groupe de threads pour avoir un seul thread et un nombre de boucles de huit. Notez que le plan de test a un contrôleur d'entrelacement externe avec deux contrôleurs d'entrelacement à l'intérieur.

Le contrôleur d'entrelacement externe alterne entre les deux contrôleurs internes. Ensuite, chaque contrôleur d'entrelacement interne alterne entre chacune des requêtes HTTP. Chaque thread JMeter enverra les requêtes dans l'ordre suivant : page d'accueil, entrelacée, page de bogue, entrelacée, page CVS, entrelacée et page FAQ, entrelacée.
Notez que le File Reporter est configuré pour stocker les résultats dans un fichier nommé « interleave-test2.dat » dans le répertoire courant.

Si les deux contrôleurs d'entrelacement sous le contrôleur d'entrelacement principal étaient à la place de simples contrôleurs, alors l'ordre serait : page d'accueil, page CVS, entrelacé, page de bogue, page FAQ, entrelacé.
Cependant, si " ignorer les blocs de sous-contrôleur " était coché sur le contrôleur d'entrelacement principal, alors l'ordre serait : page d'accueil, entrelacé, page de bogue, entrelacé, page CVS, entrelacé et page FAQ, entrelacé.
Contrôleur aléatoire ¶
Le contrôleur logique aléatoire agit de la même manière que le contrôleur d'entrelacement, sauf qu'au lieu de parcourir ses sous-contrôleurs et échantillonneurs dans l'ordre, il en choisit un au hasard à chaque passage.

Paramètres ¶
Contrôleur d'ordre aléatoire ¶
Le contrôleur d'ordre aléatoire ressemble beaucoup à un contrôleur simple en ce sens qu'il exécutera chaque élément enfant au plus une fois, mais l'ordre d'exécution des nœuds sera aléatoire.

Paramètres ¶
Contrôleur de débit ¶
Le contrôleur de débit permet à l'utilisateur de contrôler la fréquence d'exécution. Il existe deux modes :
- pourcentage d'exécution
- nombre total d'exécutions
- Pourcentage d'exécutions
- oblige le contrôleur à exécuter un certain pourcentage d'itérations dans le plan de test.
- Total des exécutions
- provoque l'arrêt de l'exécution du contrôleur après un certain nombre d'exécutions.

Paramètres ¶
Contrôleur d'exécution ¶
Le contrôleur d'exécution contrôle la durée d'exécution de ses enfants. Le contrôleur exécutera ses enfants jusqu'à ce que le ou les temps d' exécution configurés soient dépassés.

Paramètres ¶
Si Contrôleur ¶
Le contrôleur If permet à l'utilisateur de contrôler si les éléments de test situés en dessous (ses enfants) sont exécutés ou non.
Par défaut, la condition n'est évaluée qu'une seule fois lors de la saisie initiale, mais vous avez la possibilité de la faire évaluer pour chaque élément exécutable contenu dans le contrôleur.
La meilleure option (par défaut) consiste à cocher Interpréter la condition comme une expression variable ? , puis dans le champ condition vous avez 2 options :
- Option 1 : Utiliser une variable qui contient vrai ou faux
Si vous voulez tester si le dernier échantillon a réussi, vous pouvez utiliser ${JMeterThread.last_sample_ok}
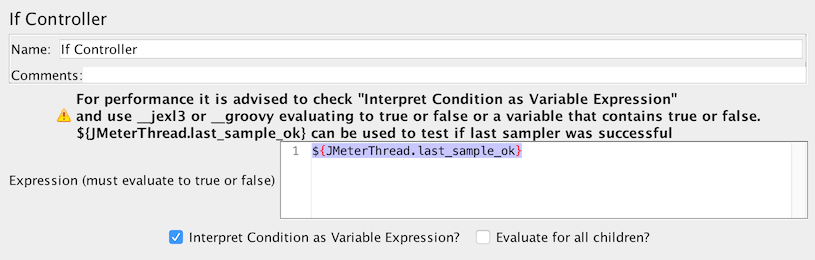
Si le contrôleur utilise la variable - Option 2 : Utiliser une fonction ( ${__jexl3()} est conseillé) pour évaluer une expression qui doit retourner vrai ou faux
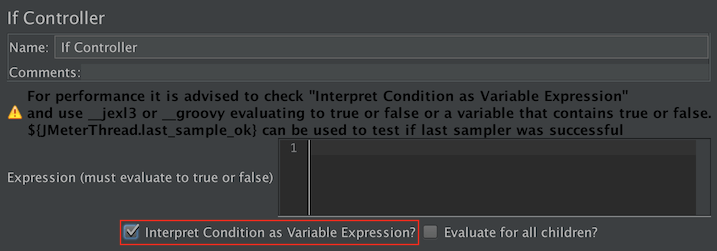
Si le contrôleur utilise l'expression

"${maVar}" == "\${maVar}"
Ou utiliser:
"${maVar}" != "\${maVar}"
pour tester si une variable est définie et n'est pas nulle.


Paramètres ¶
- ${COUNT} < 10
- "${VAR}" == "abcd"
Lorsque vous utilisez __groovy , veillez à ne pas utiliser de remplacement de variable dans la chaîne, sinon si vous utilisez une variable qui modifie le script, il ne peut pas être mis en cache. Au lieu de cela, récupérez la variable en utilisant : vars.get("myVar"). Voir les exemples Groovy ci-dessous.
- ${__groovy(vars.get("myVar") != "Invalid" )} (Groovy vérifie que myVar n'est pas égal à Invalid)
- ${__groovy(vars.get("myInt").toInteger() <=4 )} (Groovy vérifie que myInt est inférieur ou égal à 4)
- ${__groovy(vars.get("myMissing") != null )} (Groovy vérifie si la variable myMissing n'est pas définie)
- ${__jexl3(${COUNT} < 10)}
- ${RÉSULTAT}
- ${JMeterThread.last_sample_ok} (vérifier si le dernier échantillon a réussi)
Tandis que Contrôleur ¶
Le contrôleur While exécute ses enfants jusqu'à ce que la condition soit " false ".
Valeurs de condition possibles :
- vide - quitte la boucle lorsque le dernier échantillon de la boucle échoue
- LAST - quitte la boucle lorsque le dernier échantillon de la boucle échoue. Si le dernier échantillon juste avant la boucle a échoué, n'entrez pas dans la boucle.
- Sinon - quittez (ou n'entrez pas) la boucle lorsque la condition est égale à la chaîne " false "
Par exemple:
- ${VAR} - où VAR est défini sur false par un autre élément de test
- ${__jexl3(${C}==10)}
- ${__jexl3("${VAR2}"=="abcd")}
- ${_P(property)} - où la propriété est définie sur " false " ailleurs

Paramètres ¶
Contrôleur de commutateur ¶
Le contrôleur de commutateur agit comme le contrôleur d'entrelacement en ce sens qu'il exécute l'un des éléments subordonnés à chaque itération, mais plutôt que de les exécuter en séquence, le contrôleur exécute l'élément défini par la valeur du commutateur.
Si la valeur du commutateur est hors plage, il exécutera l'élément zéro, qui agit donc comme valeur par défaut pour la casse numérique. Il exécute également l'élément zéro si la valeur est la chaîne vide.
Si la valeur n'est pas numérique (et non vide), alors le contrôleur de commutateur recherche l'élément portant le même nom (la casse est significative). Si aucun des noms ne correspond, alors l'élément nommé " default " (casse non significative) est sélectionné. S'il n'y a pas de valeur par défaut, aucun élément n'est sélectionné et le contrôleur n'exécutera rien.

Paramètres ¶
Pour chaque contrôleur ¶
Un contrôleur ForEach parcourt les valeurs d'un ensemble de variables associées. Lorsque vous ajoutez des échantillonneurs (ou contrôleurs) à un contrôleur ForEach, chaque échantillon (ou contrôleur) est exécuté une ou plusieurs fois, où à chaque boucle la variable a une nouvelle valeur. L'entrée doit être composée de plusieurs variables, chacune prolongée par un trait de soulignement et un nombre. Chacune de ces variables doit avoir une valeur. Ainsi, par exemple, lorsque la variable d'entrée porte le nom inputVar , les variables suivantes doivent avoir été définies :
- entréeVar_1 = wendy
- entréeVar_2 = charles
- inputVar_3 = peter
- inputVar_4 = jean
Remarque : le séparateur " _ " est désormais facultatif.
Lorsque la variable de retour est donnée comme " returnVar ", la collection d'échantillonneurs et de contrôleurs sous le contrôleur ForEach sera exécutée 4 fois consécutives, la variable de retour ayant les valeurs ci-dessus respectives, qui peuvent ensuite être utilisées dans les échantillonneurs.
Il est particulièrement adapté à l'exécution avec le post-processeur d'expressions régulières. Cela peut "créer" les variables d'entrée nécessaires à partir des données de résultat d'une requête précédente. En omettant le séparateur " _ ", le contrôleur ForEach peut être utilisé pour parcourir les groupes en utilisant la variable d'entrée refName_g , et peut également parcourir tous les groupes dans toutes les correspondances en utilisant une variable d'entrée de la forme refName_${C }_g , où C est une variable compteur.

Paramètres ¶
Téléchargez cet exemple (voir Figure 7). Dans cet exemple, nous avons créé un plan de test qui envoie une seule requête HTTP particulière et envoie une autre requête HTTP à chaque lien pouvant être trouvé sur la page.

Nous avons configuré le groupe de threads pour un seul thread et une valeur de nombre de boucles de un. Vous pouvez voir que nous avons ajouté une requête HTTP au groupe de threads et une autre requête HTTP au contrôleur ForEach.
Après la première requête HTTP, un extracteur d'expressions régulières est ajouté, qui extrait tous les liens html de la page de retour et les place dans la variable inputVar
Dans la boucle ForEach, un échantillonneur HTTP est ajouté qui demande tous les liens qui ont été extraits de la première page HTML renvoyée.
Voici un autre exemple que vous pouvez télécharger. Cela a deux expressions régulières et des contrôleurs ForEach. Le premier RE correspond, mais le second ne correspond pas, donc aucun échantillon n'est exécuté par le second ForEach Controller

Le groupe de threads a un seul thread et un nombre de boucles de deux.
L'exemple 1 utilise l'échantillonneur JavaTest pour renvoyer la chaîne " abcd ".
L'extracteur Regex utilise l'expression (\w)\s qui correspond à une lettre suivie d'un espace et renvoie la lettre (pas l'espace). Toutes les correspondances sont préfixées par la chaîne " inputVar ".
Le contrôleur ForEach extrait toutes les variables avec le préfixe " inputVar_ ", et exécute son échantillon, en passant la valeur dans la variable " returnVar ". Dans ce cas, il définira la variable aux valeurs " a " " b " et " c " tour à tour.
L' échantillonneur For 1 est un autre échantillonneur Java qui utilise la variable de retour " returnVar " dans le cadre de l'échantillon Label et en tant que sampler Data.
Sample 2 , Regex 2 et For 2 sont presque identiques, sauf que Regex a été remplacé par " (\w)\sx ", ce qui ne correspond clairement pas. Ainsi, l' échantillonneur For 2 ne fonctionnera pas.
Contrôleur de module ¶
Le contrôleur de module fournit un mécanisme pour substituer des fragments de plan de test dans le plan de test actuel au moment de l'exécution.
Un fragment de plan de test se compose d'un contrôleur et de tous les éléments de test (échantillonneurs, etc.) qu'il contient. Le fragment peut être situé dans n'importe quel groupe de threads. Si le fragment se trouve dans un groupe de threads, son contrôleur peut être désactivé pour empêcher l'exécution du fragment sauf par le contrôleur de module. Ou vous pouvez stocker les fragments dans un groupe de threads factice et désactiver l'ensemble du groupe de threads.
Il peut y avoir plusieurs fragments, chacun avec une série différente d'échantillonneurs sous eux. Le contrôleur de module peut ensuite être utilisé pour basculer facilement entre ces multiples cas de test simplement en choisissant le contrôleur approprié dans sa liste déroulante. Cela permet d'exécuter facilement et rapidement de nombreux plans de test alternatifs.
Un nom de fragment est composé du nom du contrôleur et de tous ses noms parents. Par exemple:
Plan de test/protocole : JDBC/contrôle/contrôleur d'entrelacement (module 1)
Tous les fragments utilisés par le contrôleur de module doivent avoir un nom unique , car le nom est utilisé pour trouver le contrôleur cible lorsqu'un plan de test est rechargé. Pour cette raison, il est préférable de s'assurer que le nom du contrôleur est modifié par défaut - comme indiqué dans l'exemple ci-dessus - sinon un doublon peut être créé accidentellement lorsque de nouveaux éléments sont ajoutés au plan de test.

Paramètres ¶
Inclure le contrôleur ¶
Le contrôleur inclus est conçu pour utiliser un fichier JMX externe. Pour l'utiliser, créez un fragment de test sous le plan de test et ajoutez les échantillonneurs, contrôleurs, etc. souhaités en dessous. Enregistrez ensuite le plan de test. Le fichier est maintenant prêt à être inclus dans d'autres plans de test.
Pour plus de commodité, un groupe de threads peut également être ajouté dans le fichier JMX externe à des fins de débogage. Un contrôleur de module peut être utilisé pour référencer le fragment de test. Le groupe de threads sera ignoré pendant le processus d'inclusion.
Si le test utilise un gestionnaire de cookies ou des variables définies par l'utilisateur, celles-ci doivent être placées dans le plan de test de niveau supérieur, et non dans le fichier inclus, sinon leur fonctionnement n'est pas garanti.
Cependant, si la propriété includecontroller.prefix est définie, le contenu est utilisé pour préfixer le chemin d'accès.
Si le fichier est introuvable à l'emplacement indiqué par préfixe + nom de fichier , le contrôleur tente d'ouvrir le nom de fichier relatif au répertoire de lancement JMX.

Contrôleur de transaction ¶
Le contrôleur de transaction génère un échantillon supplémentaire qui mesure le temps total nécessaire pour effectuer les éléments de test imbriqués.
Il existe deux modes de fonctionnement :
- un échantillon supplémentaire est ajouté après les échantillons imbriqués
- un échantillon supplémentaire est ajouté en tant que parent des échantillons imbriqués
Le temps d'échantillonnage généré inclut tous les temps pour les échantillonneurs imbriqués à l'exception par défaut (depuis 2.11) des temporisateurs et du temps de traitement des pré/post processeurs sauf si la case " Inclure la durée du temporisateur et des pré-post processeurs dans l'échantillon généré " est cochée. En fonction de la résolution de l'horloge, elle peut être légèrement plus longue que la somme des échantillonneurs individuels et des temporisateurs. L'horloge peut faire tic tac après que le contrôleur a enregistré l'heure de début, mais avant le début du premier échantillon. De même à la fin.
L'échantillon généré n'est considéré comme réussi que si tous ses sous-échantillons sont réussis.
En mode parent, les échantillons individuels peuvent toujours être vus dans le Tree View Listener, mais n'apparaissent plus comme des entrées séparées dans d'autres Listeners. De plus, les sous-échantillons n'apparaissent pas dans les fichiers journaux CSV, mais ils peuvent être enregistrés dans des fichiers XML.

Paramètres ¶
Contrôleur d'enregistrement ¶
Le contrôleur d'enregistrement est un espace réservé indiquant où le serveur proxy doit enregistrer les échantillons. Pendant le test, il n'a aucun effet, similaire au contrôleur simple. Mais pendant l'enregistrement à l'aide de l' enregistreur de script de test HTTP(S) , tous les échantillons enregistrés seront par défaut enregistrés sous le contrôleur d'enregistrement.

Paramètres ¶
Contrôleur de section critique ¶
Le contrôleur de section critique garantit que ses éléments enfants (échantillonneurs/contrôleurs, etc.) seront exécutés par un seul thread car un verrou nommé sera pris avant d'exécuter les enfants du contrôleur.

La figure ci-dessous montre un exemple d'utilisation du contrôleur de section critique. Dans la figure ci-dessous, 2 contrôleurs de section critique garantissent que :
- DS2-${__threadNum} n'est exécuté que par un thread à la fois
- DS4-${__threadNum} n'est exécuté que par un seul thread à la fois

Paramètres ¶
18.3 Auditeurs ¶
La plupart des auditeurs jouent plusieurs rôles en plus d'« écouter » les résultats des tests. Ils permettent également d'afficher, d'enregistrer et de lire les résultats de test enregistrés.
Notez que les écouteurs sont traités à la fin de la portée dans laquelle ils se trouvent.
L'enregistrement et la lecture des résultats de test sont génériques. Les différents écouteurs disposent d'un panneau permettant de spécifier le fichier dans lequel les résultats seront écrits (ou lus). Par défaut, les résultats sont stockés sous forme de fichiers XML, généralement avec une extension « .jtl ». Le stockage au format CSV est l'option la plus efficace, mais il est moins détaillé que XML (l'autre option disponible).
Les écouteurs ne traitent pas les données d'échantillon en mode CLI, mais les données brutes seront enregistrées si un fichier de sortie a été configuré. Afin d'analyser les données générées par une exécution CLI, vous devez charger le fichier dans l'écouteur approprié.
Si vous souhaitez effacer toutes les données actuelles avant de charger un nouveau fichier, utilisez l'élément de menu ou avant de charger le fichier.
Les résultats peuvent être lus à partir de fichiers au format XML ou CSV. Lors de la lecture de fichiers de résultats CSV, l'en-tête (s'il est présent) est utilisé pour déterminer quels champs sont présents. Afin d'interpréter correctement un fichier CSV sans en-tête, les propriétés appropriées doivent être définies dans jmeter.properties .
Les auditeurs peuvent utiliser beaucoup de mémoire s'il y a beaucoup d'échantillons. La plupart des auditeurs conservent actuellement une copie de chaque échantillon de leur portée, à l'exception de :
- Rédacteur de données simple
- Écouteur BeanShell/JSR223
- Visualiseur de courrier
- Rapport sommaire
Les auditeurs suivants n'ont plus besoin de conserver des copies de chaque échantillon. Au lieu de cela, les échantillons avec le même temps écoulé sont agrégés. Moins de mémoire est maintenant nécessaire, surtout si la plupart des échantillons ne prennent qu'une seconde ou deux au maximum.
- Rapport agrégé
- Graphique agrégé
Pour minimiser la quantité de mémoire nécessaire, utilisez Simple Data Writer et utilisez le format CSV.
Pour plus de détails sur la configuration des éléments par défaut à enregistrer, consultez la documentation de configuration par défaut de l'écouteur . Pour plus de détails sur le contenu des fichiers de sortie, consultez le format de journal CSV ou le format de journal XML .
La figure ci-dessous montre un exemple du panneau de configuration du fichier de résultats

Paramètres
Exemple de configuration de sauvegarde des résultats ¶
Les écouteurs peuvent être configurés pour enregistrer différents éléments dans les fichiers journaux de résultats (JTL) à l'aide de la fenêtre contextuelle Config, comme indiqué ci-dessous. Les valeurs par défaut sont définies comme décrit dans la documentation de configuration par défaut de l'écouteur . Les éléments avec ( CSV ) après le nom s'appliquent uniquement au format CSV ; les éléments avec ( XML ) s'appliquent uniquement au format XML. Le format CSV ne peut actuellement pas être utilisé pour enregistrer des éléments qui incluent des sauts de ligne.
Notez que les cookies, la méthode et la chaîne de requête sont enregistrés dans le cadre de l' option " Sampler Data ".

Résultats du graphique ¶
L'écouteur Graph Results génère un graphique simple qui trace tous les temps d'échantillonnage. Au bas du graphique, l'échantillon actuel (noir), la moyenne actuelle de tous les échantillons (bleu), l'écart type actuel (rouge) et le débit actuel (vert) sont affichés en millisecondes.
Le nombre de débit représente le nombre réel de requêtes/minute traitées par le serveur. Ce calcul inclut tous les retards que vous avez ajoutés à votre test et le temps de traitement interne de JMeter. L'avantage de faire le calcul comme celui-ci est que ce nombre représente quelque chose de réel - votre serveur a en fait traité autant de requêtes par minute, et vous pouvez augmenter le nombre de threads et/ou diminuer les délais pour découvrir le débit maximum de votre serveur. Alors que si vous faisiez des calculs qui excluaient les retards et le traitement de JMeter, il serait difficile de savoir ce que vous pourriez conclure de ce nombre.

Le tableau suivant décrit brièvement les éléments du graphique. De plus amples détails sur la signification précise des termes statistiques peuvent être trouvés sur le web - par exemple Wikipedia - ou en consultant un livre sur les statistiques.
- Données - tracer les valeurs de données réelles
- Moyenne - tracez la moyenne
- Médiane - tracez la médiane (valeur médiane)
- Déviation - tracer la déviation standard (une mesure de la variation)
- Débit - tracer le nombre d'échantillons par unité de temps
Les chiffres individuels au bas de l'écran sont les valeurs actuelles. « Dernier échantillon » est le temps d'échantillonnage écoulé actuel, affiché sur le graphique en tant que « Données ».
La valeur affichée en haut à gauche du graphique est le maximum du 90 e centile du temps de réponse.
Résultats d'assertion ¶
Le visualiseur des résultats d'assertion affiche l'étiquette de chaque échantillon prélevé. Il signale également les échecs de toutes les assertions faisant partie du plan de test.

Afficher l'arborescence des résultats ¶
Il existe plusieurs façons d'afficher la réponse, sélectionnables par une liste déroulante en bas du panneau de gauche.
| Moteur de rendu | La description |
|---|---|
| Testeur CSS/JQuery | Le testeur CSS/JQuery ne fonctionne que pour les réponses textuelles. Il affiche le texte brut dans le panneau supérieur. Le bouton « Tester » permet à l'utilisateur d'appliquer le CSS/JQuery au panneau supérieur et les résultats seront affichés dans le panneau inférieur. Le moteur d'expression CSS/JQuery peut être JSoup ou Jodd, la syntaxe de ces 2 implémentations diffère légèrement. Par exemple, le sélecteur a[class=sectionlink] avec l'attribut href appliqué à la page de fonctions JMeter actuelle donne la sortie suivante : Nombre de matchs : 74 Match[1]=#fonctions Match[2]=#what_can_do Correspondance[3]=#où Correspondance[4]=#comment Correspondance[5]=#function_helper Match[6]=#fonctions Correspondance[7]=#__regexFonction Correspondance[8]=#__regexFunction_parms Match[9]=#__compteur … etc … |
| Document | La vue Document affichera le texte extrait de divers types de documents tels que Microsoft Office (Word, Excel, PowerPoint 97-2003, 2007-2010 (openxml), Apache OpenOffice (writer, calc, impress), HTML, gzip, jar/zip fichiers (liste du contenu), et certaines méta-données sur les fichiers "multimédia" comme mp3, mp4, flv, etc. La liste complète des formats pris en charge est disponible sur la page des formats Apache Tika.
Une exigence de la vue Document est de télécharger le
package binaire Apache Tika ( tika-app-xxjar ) et de le placer dans le répertoire JMETER_HOME/lib .
Si le document fait plus de 10 Mo, il ne sera pas affiché. Pour modifier cette limite, définissez la propriété JMeter document.max_size (l'unité est un octet) ou définissez-la sur 0 pour supprimer la limite.
|
| HTML | La vue HTML tente de restituer la réponse au format HTML. Le rendu HTML est susceptible de se comparer mal à la vue que l'on obtiendrait dans n'importe quel navigateur Web ; cependant, il fournit une approximation rapide qui est utile pour l'évaluation initiale des résultats. Les images, les feuilles de style, etc. ne sont pas téléchargées. |
| HTML (ressources de téléchargement) | Si l' option d' affichage HTML (télécharger les ressources) est sélectionnée, le moteur de rendu peut télécharger des images, des feuilles de style, etc. référencées par le code HTML.
|
| Source HTML formatée | Si l' option d'affichage au format source HTML est sélectionnée, le moteur de rendu affichera le code source HTML formaté et nettoyé par Jsoup .
|
| JSON | La vue JSON affichera la réponse sous forme d'arborescence (gère également JSON intégré dans JavaScript).
|
| Testeur de chemin JSON | La vue JSON Path Tester vous permettra de tester vos expressions JSON-PATH et de voir les données extraites d'une réponse particulière.
|
| Testeur JSON JMESPath | La vue JSON JMESPath Tester vous permettra de tester vos expressions JMESPath et de voir les données extraites d'une réponse particulière.
|
| Testeur d'expression régulière | La vue Regexp Tester ne fonctionne que pour les réponses textuelles. Il affiche le texte brut dans le panneau supérieur. Le bouton « Test » permet à l'utilisateur d'appliquer l'expression régulière au panneau supérieur et les résultats seront affichés dans le panneau inférieur. Le moteur d'expressions régulières est le même que celui utilisé dans l'extracteur d'expressions régulières. Par exemple, le RE (JMeter\w*).* appliqué à la page d'accueil actuelle de JMeter donne le résultat suivant : Nombre de matchs : 26 Match[1][0]=JMeter - Apache JMeter</title> Correspondance[1][1]=Jmètre Match[2][0]=JMeter" title="JMeter" border="0"/></a> Correspondance[2][1]=Jmètre Match[3][0]=JMeterCommitters">Contributeurs</a> Match[3][1]=JMeterCommitters … etc … Le premier nombre entre [] est le numéro de correspondance ; le deuxième nombre est le groupe. Le groupe [0] correspond à tout ce qui correspond à l'ensemble de l'ER. Le groupe [1] correspond à ce qui correspond au 1 er groupe, c'est-à-dire (JMeter\w*) dans ce cas. Voir Figure 9b (ci-dessous). |
| Texte | La vue Texte
par défaut affiche tout le texte contenu dans la réponse. Notez que cela ne fonctionnera que si le type de contenu de la réponse est considéré comme du texte. Si le type de contenu commence par l'un des éléments suivants, il est considéré comme binaire, sinon il est considéré comme du texte.
image/ l'audio/ vidéo/ |
| XML | La vue XML affichera la réponse sous forme d'arborescence. Tous les nœuds DTD ou nœuds Prolog n'apparaîtront pas dans l'arborescence ; cependant, la réponse peut contenir ces nœuds. Vous pouvez cliquer avec le bouton droit sur n'importe quel nœud et développer ou réduire tous les nœuds situés en dessous.
|
| Testeur XPath | Le testeur XPath ne fonctionne que pour les réponses textuelles. Il affiche le texte brut dans le panneau supérieur. Le bouton « Tester » permet à l'utilisateur d'appliquer la requête XPath au panneau supérieur et les résultats seront affichés dans le panneau inférieur. |
| Testeur d'extracteur de limite | Le Boundary Extractor Tester ne fonctionne que pour les réponses textuelles. Il affiche le texte brut dans le panneau supérieur. Le bouton « Tester » permet à l'utilisateur d'appliquer la requête Boundary Extractor au panneau supérieur et les résultats seront affichés dans le panneau inférieur. |
Faire défiler automatiquement ? l'option permet d'afficher le dernier nœud dans la sélection de l'arbre
Avec l'option Rechercher , la plupart des vues permettent également de rechercher les données affichées ; le résultat de la recherche sera mis en surbrillance dans l'affichage ci-dessus. Par exemple, la capture d'écran du panneau de configuration ci-dessous montre un résultat de la recherche de " Java ". Notez que la recherche s'effectue sur le texte visible, vous pouvez donc obtenir des résultats différents lors de la recherche dans les vues Texte et HTML.
Remarque : L'expression régulière utilise le moteur Java (pas le moteur ORO comme la vue Regular Expression Extractor ou Regexp Tester).
Si aucun type de contenu n'est fourni, le contenu ne sera affiché dans aucun des panneaux de données de réponse. Vous pouvez utiliser Enregistrer les réponses dans un fichier pour enregistrer les données dans ce cas. Notez que les données de réponse seront toujours disponibles dans le résultat de l'échantillon, elles sont donc toujours accessibles à l'aide des post-processeurs.
Si les données de réponse sont supérieures à 200 Ko, elles ne seront pas affichées. Pour modifier cette limite, définissez la propriété JMeter view.results.tree.max_size . Vous pouvez également enregistrer l'intégralité de la réponse dans un fichier à l'aide de Enregistrer les réponses dans un fichier .
Des moteurs de rendu supplémentaires peuvent être créés. La classe doit implémenter l'interface org.apache.jmeter.visualizers.ResultRenderer et/ou étendre la classe abstraite org.apache.jmeter.visualizers.SamplerResultTab , et le code compilé doit être disponible pour JMeter (par exemple en l'ajoutant à la lib/ répertoire ext ).

Le panneau de configuration (ci-dessus) montre un exemple d'affichage HTML.
La figure 9 (ci-dessous) montre un exemple d'affichage XML.
La figure 9a (ci-dessous) montre un exemple d'affichage d'un testeur Regexp.
La figure 9b (ci-dessous) montre un exemple d'affichage de document.



Rapport agrégé ¶
Le débit est calculé du point de vue de la cible de l'échantillonneur (par exemple le serveur distant dans le cas des échantillons HTTP). JMeter prend en compte le temps total pendant lequel les requêtes ont été générées. Si d'autres échantillonneurs et minuteries se trouvent dans le même thread, ceux-ci augmenteront le temps total et réduiront donc la valeur de débit. Ainsi, deux échantillonneurs identiques portant des noms différents auront la moitié du débit de deux échantillonneurs portant le même nom. Il est important de choisir correctement les noms des échantillonneurs pour obtenir les meilleurs résultats du rapport agrégé.
Le calcul des valeurs de la médiane et de la ligne de 90 % (90 e centile ) nécessite de la mémoire supplémentaire. JMeter combine maintenant des échantillons avec le même temps écoulé, donc beaucoup moins de mémoire est utilisée. Cependant, pour les échantillons qui prennent plus de quelques secondes, il est probable que moins d'échantillons auront des temps identiques, auquel cas plus de mémoire sera nécessaire. Notez que vous pouvez utiliser cet écouteur par la suite pour recharger un fichier de résultats CSV ou XML, ce qui est la méthode recommandée pour éviter les impacts sur les performances. Voir le rapport de synthèse pour un récepteur similaire qui ne stocke pas d'échantillons individuels et nécessite donc une mémoire constante.
- Étiquette - L'étiquette de l'échantillon. Si « Inclure le nom du groupe dans l'étiquette ? » est sélectionné, le nom du groupe de threads est ajouté en tant que préfixe. Cela permet aux étiquettes identiques de différents groupes de fils d'être assemblées séparément si nécessaire.
- # Samples - Le nombre d'échantillons avec la même étiquette
- Moyenne - Le temps moyen d'un ensemble de résultats
- Médiane - La médiane est le temps au milieu d'un ensemble de résultats. 50 % des échantillons n'ont pas pris plus de temps ; le reste a pris au moins autant de temps.
- 90% Line - 90% des échantillons n'ont pas pris plus de temps. Les échantillons restants ont pris au moins aussi longtemps que cela. (90 e centile )
- 95% Line - 95% des échantillons n'ont pas pris plus de temps. Les échantillons restants ont pris au moins aussi longtemps que cela. (95 e centile )
- 99% Line - 99% des échantillons n'ont pas pris plus de temps. Les échantillons restants ont pris au moins aussi longtemps que cela. (99 e centile )
- Min - Le temps le plus court pour les échantillons avec la même étiquette
- Max - Le temps le plus long pour les échantillons avec la même étiquette
- % d'erreur - Pourcentage de requêtes comportant des erreurs
- Débit - le débit est mesuré en requêtes par seconde/minute/heure. L'unité de temps est choisie de manière à ce que le taux affiché soit d'au moins 1,0. Lorsque le débit est enregistré dans un fichier CSV, il est exprimé en requêtes/seconde, c'est-à-dire que 30,0 requêtes/minute sont enregistrées sous la forme 0,5.
- Received KB/sec - Le débit mesuré en kilo-octets reçus par seconde
- Sent KB/sec - Le débit mesuré en kilo-octets envoyés par seconde
Les temps sont en millisecondes.

La figure ci-dessous montre un exemple de sélection de la case à cocher " Inclure le nom du groupe ".

Afficher les résultats dans le tableau ¶
Par défaut, il n'affiche que les échantillons principaux (parents) ; il n'affiche pas les sous-échantillons (échantillons enfants). JMeter a une case à cocher " Child Samples? ". Si cette option est sélectionnée, les sous-échantillons sont affichés à la place des échantillons principaux.

Éditeur de données simple ¶
Graphique agrégé ¶

La figure ci-dessous montre un exemple de paramétrage pour tracer ce graphique.

Paramètres ¶
- Colonnes à afficher : choisissez la ou les colonnes à afficher dans le graphique.
- Couleur des rectangles : cliquez sur le rectangle de couleur de droite pour ouvrir une boîte de dialogue contextuelle afin de choisir une couleur personnalisée pour la colonne.
- Couleur de premier plan Permet de changer la couleur du texte de la valeur.
- Police de valeur : permet de définir les paramètres de police pour le texte.
- Dessiner une barre de contours ? Pour tracer ou non la ligne de bordure sur le graphique à barres
- Afficher le groupement de numéros ? Afficher ou non le regroupement des nombres dans les libellés de l'axe Y.
- Étiquettes de valeur verticales ? Changer l'orientation de l'étiquette de valeur. (La valeur par défaut est horizontale)
-
Sélection d'étiquette de colonne : filtrer par étiquette de résultat. Une expression régulière peut être utilisée, exemple : .*Transaction.*
Avant d'afficher le graphique, cliquez sur le bouton Appliquer le filtre pour actualiser les données internes.
Graphique du temps de réponse ¶

La figure ci-dessous montre un exemple de paramétrage pour tracer ce graphique.

Paramètres ¶
Visualiseur de courrier ¶
Le visualiseur de messagerie peut être configuré pour envoyer des e-mails si une exécution de test reçoit trop de réponses d'échec du serveur.

Paramètres ¶
Écouteur BeanShell ¶
Le BeanShell Listener permet l'utilisation de BeanShell pour le traitement des échantillons pour la sauvegarde, etc.
Pour plus de détails sur l'utilisation de BeanShell, veuillez consulter le site Web de BeanShell.
L'élément de test prend en charge les méthodes ThreadListener et TestListener . Ceux-ci doivent être définis dans le fichier d'initialisation. Voir le fichier BeanShellListeners.bshrc pour des exemples de définitions.

Paramètres ¶
- Paramètres
- chaîne contenant les paramètres comme une seule variable
- bsh.args
- Tableau de chaînes contenant des paramètres, divisés en espaces blancs
Avant d'invoquer le script, certaines variables sont configurées dans l'interpréteur BeanShell :
- log - ( Logger ) - peut être utilisé pour écrire dans le fichier journal
- ctx - ( JMeterContext ) - donne accès au contexte
-
vars - ( JMeterVariables ) - donne un accès en lecture/écriture aux variables :
vars.get(clé); vars.put(clé,val); vars.putObject("OBJ1",nouvel objet()); - props - (JMeterProperties - classe java.util.Properties ) - par exemple props.get("START.HMS"); props.put("PROP1","1234");
- sampleResult , prev - ( SampleResult ) - donne accès au précédent SampleResult
- sampleEvent ( SampleEvent ) donne accès à l'événement échantillon courant
Pour plus de détails sur toutes les méthodes disponibles sur chacune des variables ci-dessus, veuillez consulter la Javadoc
Si la propriété beanshell.listener.init est définie, elle est utilisée pour charger un fichier d'initialisation, qui peut être utilisé pour définir des méthodes, etc. à utiliser dans le script BeanShell.
Rapport de synthèse ¶
Le débit est calculé du point de vue de la cible de l'échantillonneur (par exemple le serveur distant dans le cas des échantillons HTTP). JMeter prend en compte le temps total pendant lequel les requêtes ont été générées. Si d'autres échantillonneurs et minuteries se trouvent dans le même thread, ceux-ci augmenteront le temps total et réduiront donc la valeur de débit. Ainsi, deux échantillonneurs identiques portant des noms différents auront la moitié du débit de deux échantillonneurs portant le même nom. Il est important de choisir correctement les étiquettes de l'échantillonneur pour obtenir les meilleurs résultats du rapport.
- Étiquette - L'étiquette de l'échantillon. Si « Inclure le nom du groupe dans l'étiquette ? » est sélectionné, le nom du groupe de threads est ajouté en tant que préfixe. Cela permet aux étiquettes identiques de différents groupes de fils d'être assemblées séparément si nécessaire.
- # Samples - Le nombre d'échantillons avec la même étiquette
- Moyenne - Le temps écoulé moyen d'un ensemble de résultats
- Min - Le temps écoulé le plus bas pour les échantillons avec la même étiquette
- Max - Le temps écoulé le plus long pour les échantillons avec la même étiquette
- Std. Dév. - l' écart type du temps écoulé de l'échantillon
- % d'erreur - Pourcentage de requêtes comportant des erreurs
- Débit - le débit est mesuré en requêtes par seconde/minute/heure. L'unité de temps est choisie de manière à ce que le taux affiché soit d'au moins 1,0 . Lorsque le débit est enregistré dans un fichier CSV, il est exprimé en requêtes/seconde, c'est-à-dire que 30,0 requêtes/minute sont enregistrées sous la forme 0,5 .
- Received KB/sec - Le débit mesuré en kilo-octets par seconde
- Sent KB/sec - Le débit mesuré en kilo-octets par seconde
- Moy. Octets - taille moyenne de l'échantillon de réponse en octets.
Les temps sont en millisecondes.

La figure ci-dessous montre un exemple de sélection de la case à cocher " Inclure le nom du groupe ".

Enregistrer les réponses dans un fichier ¶
Cet élément de test peut être placé n'importe où dans le plan de test. Pour chaque échantillon dans sa portée, il créera un fichier de données de réponse. Cela sert principalement à créer des tests fonctionnels, mais cela peut également être utile lorsque la réponse est trop volumineuse pour être affichée dans l' écouteur de l' arborescence des résultats . Le nom de fichier est créé à partir du préfixe spécifié, suivi d'un nombre (sauf si cette option est désactivée, voir ci-dessous). L'extension de fichier est créée à partir du type de document, s'il est connu. Si elle n'est pas connue, l'extension de fichier est définie sur ' inconnu'. Si la numérotation est désactivée et que l'ajout d'un suffixe est désactivé, le préfixe de fichier est considéré comme le nom de fichier complet. Cela permet de générer un nom de fichier fixe si nécessaire. Le nom du fichier généré est stocké dans l'exemple de réponse et peut être enregistré dans le fichier de sortie du journal de test si nécessaire.
L'échantillon actuel est enregistré en premier, suivi de tous les sous-échantillons (échantillons enfants). Si un nom de variable est fourni, les noms des fichiers sont enregistrés dans l'ordre d'apparition des sous-échantillons. Voir ci-dessous.

Paramètres ¶
Si les dossiers parents dans le préfixe n'existent pas, JMeter les créera et arrêtera le test en cas d'échec.
Auditeur JSR223 ¶
L'écouteur JSR223 permet d'appliquer le code de script JSR223 aux résultats d'échantillon.
Paramètres ¶
- Paramètres
- chaîne contenant les paramètres comme une seule variable
- arguments
- Tableau de chaînes contenant des paramètres, divisés en espaces blancs
Avant d'invoquer le script, certaines variables sont configurées. Notez qu'il s'agit de variables JSR223 - c'est-à-dire qu'elles peuvent être utilisées directement dans le script.
- Journal
- ( Logger ) - peut être utilisé pour écrire dans le fichier journal
- Étiquette
- l'étiquette de chaîne
- Nom de fichier
- le nom du fichier de script (le cas échéant)
- Paramètres
- les paramètres (sous forme de chaîne)
- arguments
- les paramètres sous la forme d'un tableau String (divisé en espaces blancs)
- ctx
- ( JMeterContext ) - donne accès au contexte
- vars
- ( JMeterVariables ) - donne un accès en lecture/écriture aux variables :
vars.get(clé); vars.put(clé,val); vars.putObject("OBJ1",nouvel objet()); vars.getObject("OBJ2"); - accessoires
- (JMeterProperties - classe java.util.Properties ) - par exemple props.get("START.HMS"); props.put("PROP1","1234");
- exemple de résultat , précédent
- ( SampleResult ) - donne accès au SampleResult
- exemple d'événement
- ( SampleEvent ) - donne accès au SampleEvent
- échantillonneur
- ( Sampler )- donne accès au dernier sampler
- DEHORS
- System.out - par exemple OUT.println("message")
Pour plus de détails sur toutes les méthodes disponibles sur chacune des variables ci-dessus, veuillez consulter la Javadoc
Générer des résultats récapitulatifs ¶
# Définissez la propriété suivante pour démarrer automatiquement un récapitulatif avec ce nom # (s'applique uniquement au mode CLI) #summariser.name=résumé # # intervalle entre les résumés (en secondes) par défaut 3 minutes #summariser.interval=30 # # Écrire des messages dans le fichier journal #summariser.log=true # # Écrire des messages dans System.out #summariser.out=trueCet élément est principalement destiné aux exécutions par lots (CLI). La sortie ressemble à ceci :
label + 16 in 0:00:12 = 1.3/s Moy : 1608 Min : 1163 Max : 2009 Err : 0 (0.00%) Actif : 5 Démarré : 5 Terminé : 0 label + 82 in 0:00:30 = 2.7/s Moy : 1518 Min : 1003 Max : 2020 Err : 0 (0.00%) Actif : 5 Démarré : 5 Terminé : 0 étiquette = 98 en 0:00:42 = 2,3/s Moy : 1533 Min : 1003 Max : 2020 Err : 0 (0,00 %) label + 85 en 0:00:30 = 2,8/s Moy : 1505 Min : 1008 Max : 2005 Err : 0 (0,00%) Actif : 5 Démarré : 5 Terminé : 0 étiquette = 183 en 0:01:13 = 2,5/s Moy : 1520 Min : 1003 Max : 2020 Err : 0 (0,00%) label + 79 en 0:00:30 = 2,7/s Moy : 1578 Min : 1089 Max : 2012 Err : 0 (0,00%) Actif : 5 Démarré : 5 Terminé : 0 étiquette = 262 en 0:01:43 = 2,6/s Moy : 1538 Min : 1003 Max : 2020 Err : 0 (0,00%) label + 80 en 0:00:30 = 2,7/s Moy : 1531 Min : 1013 Max : 2014 Err : 0 (0,00%) Actif : 5 Démarré : 5 Terminé : 0 étiquette = 342 en 0:02:12 = 2,6/s Moy : 1536 Min : 1003 Max : 2020 Err : 0 (0,00 %) label + 83 in 0:00:31 = 2.7/s Moy : 1512 Min : 1003 Max : 1982 Err : 0 (0.00%) Actif : 5 Démarré : 5 Terminé : 0 étiquette = 425 en 0:02:43 = 2,6/s Moy : 1531 Min : 1003 Max : 2020 Err : 0 (0,00 %) label + 83 in 0:00:29 = 2.8/s Moy : 1487 Min : 1023 Max : 2013 Err : 0 (0.00%) Actif : 5 Démarré : 5 Terminé : 0 étiquette = 508 en 0:03:12 = 2,6/s Moy : 1524 Min : 1003 Max : 2020 Err : 0 (0,00 %) label + 78 en 0:00:30 = 2,6/s Moy : 1594 Min : 1013 Max : 2016 Err : 0 (0,00%) Actif : 5 Démarré : 5 Terminé : 0 étiquette = 586 en 0:03:43 = 2,6/s Moy : 1533 Min : 1003 Max : 2020 Err : 0 (0,00 %) label + 80 en 0:00:30 = 2,7/s Moy : 1516 Min : 1013 Max : 2005 Err : 0 (0,00%) Actif : 5 Démarré : 5 Terminé : 0 étiquette = 666 en 0:04:12 = 2,6/s Moy : 1531 Min : 1003 Max : 2020 Err : 0 (0,00 %) label + 86 en 0:00:30 = 2,9/s Moy : 1449 Min : 1004 Max : 2017 Err : 0 (0,00 %) Actif : 5 Démarré : 5 Terminé : 0 étiquette = 752 en 0:04:43 = 2,7/s Moy : 1522 Min : 1003 Max : 2020 Err : 0 (0,00 %) label + 65 en 0:00:24 = 2,7/s Moy : 1579 Min : 1007 Max : 2003 Err : 0 (0,00 %) Actif : 0 Démarré : 5 Terminé : 5 étiquette = 817 en 0:05:07 = 2,7/s Moy : 1526 Min : 1003 Max : 2020 Err : 0 (0,00%)Le " label " est le nom de l'élément. Le "+" signifie que la ligne est une ligne delta, c'est-à-dire qu'elle montre les changements depuis la dernière sortie.
Le "=" signifie que la ligne est une ligne de total, c'est-à-dire qu'elle indique le total cumulé.
Les entrées du fichier journal JMeter incluent également des horodatages. L'exemple " 817 en 0:05:07 = 2,7/s " signifie qu'il y a eu 817 échantillons enregistrés en 5 minutes et 7 secondes, et cela équivaut à 2,7 échantillons par seconde.
Les durées Avg (Moyenne), Min (Minimum) et Max (Maximum) sont en millisecondes.
" Err " signifie le nombre d'erreurs (également indiqué en pourcentage).
Les deux dernières lignes apparaîtront à la fin d'un test. Ils ne seront pas synchronisés avec la limite de temps appropriée. Notez que les deltas initial et final peuvent être inférieurs à l'intervalle (dans l'exemple ci-dessus, il s'agit de 30 secondes). Le premier delta sera généralement inférieur, car JMeter se synchronise sur la limite de l'intervalle. Le dernier delta sera inférieur, car le test ne se terminera généralement pas sur une limite d'intervalle exacte.
L'étiquette est utilisée pour regrouper les résultats des échantillons. Donc, si vous avez plusieurs groupes de threads et que vous souhaitez les résumer tous, utilisez la même étiquette - ou ajoutez le récapitulatif au plan de test (afin que tous les groupes de threads soient concernés). Différents regroupements de résumés peuvent être mis en œuvre en utilisant des étiquettes appropriées et en ajoutant les résumés aux parties appropriées du plan de test.
Ce n'est pas un bogue mais un choix de conception permettant de résumer à travers les groupes de threads.

Paramètres ¶
Visualiseur d'assertion de comparaison ¶

Paramètres ¶
Auditeur principal ¶

Paramètres ¶
Les paramètres suivants s'appliquent à l' implémentation de GraphiteBackendListenerClient :
Paramètres ¶
Voir aussi Résultats en temps réel pour plus de détails.

Depuis JMeter 3.2, une implémentation qui permet d'écrire directement dans InfluxDB avec un schéma personnalisé. Il s'appelle InfluxdbBackendListenerClient . Les paramètres suivants s'appliquent à l' implémentation InfluxdbBackendListenerClient :
Paramètres ¶
Voir aussi Résultats en temps réel et Annotations Influxdb dans Grafana pour plus de détails. Il existe également une sous- section sur la configuration de l'écouteur pour InfluxDB v2 .
Depuis JMeter 5.4, une implémentation qui écrit tous les exemples de résultats dans InfluxDB. Il s'appelle InfluxDBRawBackendListenerClient . Il convient de noter que cela utilisera plus de ressources que InfluxdbBackendListenerClient , à la fois par JMeter et InfluxDB en raison de l'augmentation des données et des écritures individuelles. Les paramètres suivants s'appliquent à l' implémentation InfluxDBRawBackendListenerClient :
Paramètres ¶
18.4 Éléments de configuration ¶
Les éléments de configuration peuvent être utilisés pour définir des valeurs par défaut et des variables pour une utilisation ultérieure par les échantillonneurs. Notez que ces éléments sont traités au début de la portée dans laquelle ils se trouvent, c'est-à-dire avant tout échantillonneur dans la même portée.
Configuration du jeu de données CSV ¶
CSV Data Set Config est utilisé pour lire les lignes d'un fichier et les diviser en variables. Il est plus facile à utiliser que les fonctions __CSVRead() et __StringFromFile() . Il est bien adapté à la gestion d'un grand nombre de variables et est également utile pour tester avec des valeurs "aléatoires" et uniques.
La génération de valeurs aléatoires uniques au moment de l'exécution est coûteuse en termes de CPU et de mémoire, il suffit donc de créer les données avant le test. Si nécessaire, les données "aléatoires" du fichier peuvent être utilisées en conjonction avec un paramètre d'exécution pour créer différents ensembles de valeurs à partir de chaque exécution - par exemple en utilisant la concaténation - ce qui est beaucoup moins cher que de tout générer au moment de l'exécution.
JMeter permet de citer des valeurs ; cela permet à la valeur de contenir un délimiteur. Si « autoriser les données entre guillemets » est activé, une valeur peut être entourée de guillemets doubles. Ceux-ci sont supprimés. Pour inclure des guillemets dans un champ entre guillemets, utilisez deux guillemets. Par exemple:
1,"2,3","4""5" => 1 2,3 4"5
JMeter prend en charge les fichiers CSV qui ont une ligne d'en-tête définissant les noms de colonne. Pour l'activer, laissez le champ " Noms des variables " vide. Le délimiteur correct doit être fourni.
JMeter prend en charge les fichiers CSV avec des données citées qui incluent de nouvelles lignes.
Par défaut, le fichier n'est ouvert qu'une seule fois et chaque thread utilisera une ligne différente du fichier. Cependant, l'ordre dans lequel les lignes sont passées aux threads dépend de l'ordre dans lequel elles s'exécutent, qui peut varier entre les itérations. Les lignes sont lues au début de chaque itération de test. Le nom de fichier et le mode sont résolus lors de la première itération.
Voir la description du mode Partager ci-dessous pour des options supplémentaires. Si vous souhaitez que chaque thread ait son propre ensemble de valeurs, vous devrez créer un ensemble de fichiers, un pour chaque thread. Par exemple test1.csv , test2.csv , …, test n .csv . Utilisez le nom de fichier test${__threadNum}.csv et définissez le " Mode de partage " sur " Thread actuel ".
Dans un cas particulier, la chaîne " \t " (sans guillemets) dans le champ délimiteur est traitée comme une tabulation.
Lorsque la fin du fichier ( EOF ) est atteinte et que l'option recycle est true , la lecture recommence à la première ligne du fichier.
Si l'option recycle est false et stopThread est false , toutes les variables sont définies sur <EOF> lorsque la fin du fichier est atteinte. Cette valeur peut être modifiée en définissant la propriété JMeter csvdataset.eofstring .
Si l'option Recycle est false et Stop Thread est true , atteindre EOF entraînera l'arrêt du thread.

Paramètres ¶
- Tous les threads - (par défaut) le fichier est partagé entre tous les threads.
- Groupe de threads actuel - chaque fichier est ouvert une fois pour chaque groupe de threads dans lequel l'élément apparaît
- Thread actuel - chaque fichier est ouvert séparément pour chaque thread
- Identifiant - tous les threads partageant le même identifiant partagent le même fichier. Ainsi, par exemple, si vous avez 4 groupes de threads, vous pouvez utiliser un identifiant commun pour deux ou plusieurs groupes afin de partager le fichier entre eux. Ou vous pouvez utiliser le numéro de thread pour partager le fichier entre les mêmes numéros de thread dans différents groupes de threads.
Paramètres par défaut des requêtes FTP ¶

Gestionnaire de cache DNS ¶
L'élément DNS Cache Manager permet de tester les applications, qui ont plusieurs serveurs derrière des équilibreurs de charge (CDN, etc.), lorsque l'utilisateur reçoit du contenu de différentes adresses IP. Par défaut, JMeter utilise le cache DNS JVM. C'est pourquoi un seul serveur du cluster reçoit la charge. Le gestionnaire de cache DNS résout les noms de chaque thread séparément à chaque itération et enregistre les résultats de la résolution dans son cache DNS interne, qui est indépendant des caches DNS JVM et OS.
Un mappage pour les hôtes statiques peut être utilisé pour simuler quelque chose comme le fichier /etc/hosts . Ces entrées seront préférées au résolveur personnalisé. Utiliser un résolveur DNS personnalisé doit être activé si vous souhaitez utiliser ce mappage.
Supposons que vous ayez un serveur de test, que vous souhaitez atteindre avec un nom, qui n'est pas (encore) configuré dans vos serveurs DNS. Pour notre exemple, ce serait www.example.com pour le nom du serveur, que vous souhaitez atteindre à l'adresse IP du serveur a123.another.example.org .
Vous pouvez changer de poste de travail et ajouter une entrée à votre fichier /etc/hosts - ou l'équivalent pour votre système d'exploitation, ou ajouter une entrée à la table des hôtes statiques du gestionnaire de cache DNS.
Vous devez taper www.example.com dans la première colonne ( Host ) et a123.another.example.org dans la deuxième colonne ( Hostname ou IP address ). Comme le nom de la deuxième colonne l'indique, vous pouvez même y utiliser l'adresse IP de votre serveur de test.
L'adresse IP du serveur de test sera recherchée à l'aide du résolveur DNS personnalisé. Si aucun n'est fourni, le résolveur DNS du système sera utilisé.
Vous pouvez maintenant utiliser www.example.com dans vos échantillonneurs HTTPClient4 et les requêtes seront adressées à a123.another.example.org avec tous les en-têtes définis sur www.example.com .

Paramètres ¶
Gestionnaire d'autorisations HTTP ¶
Le gestionnaire d'autorisations vous permet de spécifier une ou plusieurs connexions utilisateur pour les pages Web restreintes à l'aide de l'authentification du serveur. Vous voyez ce type d'authentification lorsque vous utilisez votre navigateur pour accéder à une page restreinte et que votre navigateur affiche une boîte de dialogue de connexion. JMeter transmet les informations de connexion lorsqu'il rencontre ce type de page.
Les en-têtes d'autorisation peuvent ne pas s'afficher dans l' onglet « Requête » de Tree View Listener . L'implémentation Java effectue une authentification préemptive, mais elle ne renvoie pas l'en-tête d'autorisation lorsque JMeter récupère les en-têtes. L'implémentation HttpComponents (HC 4.5.X) est par défaut préemptive depuis 3.2 et l'en-tête sera affiché. Pour désactiver cela, définissez les valeurs comme ci-dessous, auquel cas l'authentification ne sera effectuée qu'en réponse à un défi.
Dans le fichier jmeter.properties définissez httpclient4.auth.preemptive=false

Paramètres ¶
- Java
- DE BASE
- Client HTTP 4
- BASIC , DIGEST et Kerberos
Configuration Kerberos :
Pour configurer Kerberos, vous devez configurer au moins deux propriétés système JVM :
- -Djava.security.krb5.conf=krb5.conf
- -Djava.security.auth.login.config=jaas.conf
Vous pouvez également configurer ces deux propriétés dans le fichier bin/system.properties . Regardez les deux exemples de fichiers de configuration ( krb5.conf et jaas.conf ) situés dans le dossier bin de JMeter pour des références à plus de documentation, et ajustez-les pour qu'ils correspondent à votre configuration Kerberos.
La délégation des informations d'identification est désactivée par défaut pour SPNEGO. Si vous souhaitez l'activer, vous pouvez le faire en définissant la propriété kerberos.spnego.delegate_cred sur true .
Lors de la génération d'un SPN pour l'authentification Kerberos SPNEGO, IE et Firefox omettent le numéro de port de l'URL. Chrome a une option ( --enable-auth-negotiate-port ) pour inclure le numéro de port s'il diffère des numéros standard ( 80 et 443 ). Ce comportement peut être émulé en définissant la propriété JMeter suivante comme ci-dessous.
Dans jmeter.properties ou user.properties , définissez :
- kerberos.spnego.strip_port=false
Les contrôles:
- Bouton Ajouter - Ajouter une entrée au tableau des autorisations.
- Bouton Supprimer - Supprimer l'entrée de table actuellement sélectionnée.
- Bouton Charger - Charger une table d'autorisation précédemment enregistrée et ajouter les entrées aux entrées de table d'autorisation existantes.
- Bouton Enregistrer sous - Enregistrer la table d'autorisation actuelle dans un fichier.
Téléchargez cet exemple. Dans cet exemple, nous avons créé un plan de test sur un serveur local qui envoie trois requêtes HTTP, deux nécessitant une connexion et l'autre est ouverte à tous. Voir la figure 10 pour voir la composition de notre plan de test. Sur notre serveur, nous avons un répertoire restreint nommé « secret », qui contient deux fichiers, « index.html » et « index2.html ». Nous avons créé un identifiant de connexion nommé " kevin ", qui a un mot de passe " spot ". Ainsi, dans notre gestionnaire d'autorisations, nous avons créé une entrée pour le répertoire restreint ainsi qu'un nom d'utilisateur et un mot de passe (voir figure 11). Les deux requêtes HTTP nommées " SecretPage1 " et " SecretPage2 "/secret/index.html " et " /secret/index2.html ". L'autre requête HTTP, nommée " NoSecretPage " fait une requête à " /index.html ".


Lorsque nous exécutons le plan de test, JMeter recherche dans le tableau d'autorisation l'URL qu'il demande. Si l'URL de base correspond à l'URL, alors JMeter transmet ces informations avec la demande.
Gestionnaire de cache HTTP ¶
Le gestionnaire de cache HTTP est utilisé pour ajouter une fonctionnalité de mise en cache aux requêtes HTTP dans son champ d'application afin de simuler la fonctionnalité de cache du navigateur. Chaque thread d'utilisateur virtuel a son propre cache. Par défaut, Cache Manager stockera jusqu'à 5000 éléments dans le cache par thread d'utilisateur virtuel, en utilisant l'algorithme LRU. Utilisez la propriété " maxSize " pour modifier cette valeur. Notez que plus vous augmentez cette valeur, plus HTTP Cache Manager consommera de la mémoire, veillez donc à adapter l' option -Xmx JVM en conséquence.
Si un échantillon réussit (c'est-à-dire qu'il a le code de réponse 2xx ), les valeurs Last-Modified et Etag (et Expired si pertinent) sont enregistrées pour l'URL. Avant d'exécuter l'exemple suivant, l'échantillonneur vérifie s'il existe une entrée dans le cache et, si c'est le cas, les en-têtes conditionnels If-Last-Modified et If-None-Match sont définis pour la demande.
De plus, si l'option « Utiliser l'en-tête Cache-Control/Expires » est sélectionnée, la valeur Cache-Control / Expires est vérifiée par rapport à l'heure actuelle. Si la demande est une demande GET et que l'horodatage est dans le futur, l'échantillonneur revient immédiatement, sans demander l'URL au serveur distant. Ceci est destiné à imiter le comportement du navigateur. Notez que si l'en- tête Cache-Control est " no-cache ", la réponse sera stockée dans le cache comme pré-expirée, donc générera une requête GET conditionnelle. Si Cache-Control a une autre valeur, le " max-age" L'option d'expiration est traitée pour calculer la durée de vie de l'entrée, si elle est manquante, l'en-tête d'expiration sera utilisé, si l'entrée manquante sera également mise en cache comme spécifié dans la section 13.2.4 de la RFC 2616 en utilisant l'heure de dernière modification et la date de réponse.

Paramètres ¶
Gestionnaire de cookies HTTP ¶
L'élément Cookie Manager a deux fonctions :
premièrement, il stocke et envoie des cookies comme un navigateur Web. Si vous avez une requête HTTP et que la réponse contient un cookie, le gestionnaire de cookies stocke automatiquement ce cookie et l'utilisera pour toutes les demandes futures adressées à ce site Web particulier. Chaque thread JMeter possède sa propre "zone de stockage des cookies". Ainsi, si vous testez un site Web qui utilise un cookie pour stocker les informations de session, chaque thread JMeter aura sa propre session. Notez que ces cookies n'apparaissent pas sur l'affichage du gestionnaire de cookies, mais ils peuvent être vus à l'aide de l' écouteur
de l' arborescence des résultats .
JMeter vérifie que les cookies reçus sont valides pour l'URL. Cela signifie que les cookies inter-domaines ne sont pas stockés. Si vous avez un comportement buggé ou souhaitez que les cookies inter-domaines soient utilisés, définissez la propriété JMeter " CookieManager.check.cookies=false ".
Les cookies reçus peuvent être stockés en tant que variables de thread JMeter. Pour enregistrer les cookies en tant que variables, définissez la propriété " CookieManager.save.cookies=true ". De plus, les noms des cookies sont préfixés par " COOKIE_ " avant d'être stockés (ceci évite la corruption accidentelle des variables locales) Pour revenir au comportement d'origine, définissez la propriété " CookieManager.name.prefix= " (un ou plusieurs espaces). Si activé, la valeur d'un cookie portant le nom TEST peut être appelée ${COOKIE_TEST} .
Deuxièmement, vous pouvez ajouter manuellement un cookie au gestionnaire de cookies. Cependant, si vous faites cela, le cookie sera partagé par tous les threads JMeter.
Notez que ces cookies sont créés avec une date d'expiration lointaine dans le futur
Les cookies avec des valeurs nulles sont ignorés par défaut. Cela peut être modifié en définissant la propriété JMeter : CookieManager.delete_null_cookies=false . Notez que cela s'applique également aux cookies définis manuellement - ces cookies seront supprimés de l'affichage lors de sa mise à jour. Notez également que le nom du cookie doit être unique - si un deuxième cookie est défini avec le même nom, il remplacera le premier.

Paramètres ¶
[Remarque : si vous avez un site Web à tester avec une adresse IPv6, choisissez HC4CookieHandler (conforme à IPv6)]
Le " domaine " est le nom d'hôte du serveur (sans http:// ); le port est actuellement ignoré.
Valeurs par défaut des requêtes HTTP ¶
Cet élément vous permet de définir les valeurs par défaut utilisées par vos contrôleurs de requête HTTP. Par exemple, si vous créez un plan de test avec 25 contrôleurs de requêtes HTTP et que toutes les requêtes sont envoyées au même serveur, vous pouvez ajouter un seul élément HTTP Request Defaults avec le champ " Server Name or IP " rempli. Ensuite , lorsque vous ajoutez les 25 contrôleurs HTTP Request, laissez le champ " Server Name or IP " vide. Les contrôleurs hériteront de cette valeur de champ de l'élément HTTP Request Defaults.


Paramètres ¶
Gestionnaire d'en-tête HTTP ¶
Le gestionnaire d'en-têtes vous permet d'ajouter ou de remplacer les en-têtes de requête HTTP.
JMeter prend désormais en charge plusieurs gestionnaires d'en-tête . Les entrées d'en-tête sont fusionnées pour former la liste de l'échantillonneur. Si une entrée à fusionner correspond à un nom d'en-tête existant, elle remplace l'entrée précédente. Cela permet de configurer un ensemble d'en-têtes par défaut et d'appliquer des ajustements à des échantillonneurs particuliers. Notez qu'une valeur vide pour un en-tête ne supprime pas un en-tête existant, elle remplace simplement sa valeur.

Paramètres ¶
Téléchargez cet exemple. Dans cet exemple, nous avons créé un plan de test qui indique à JMeter de remplacer l'en-tête de requête par défaut " User-Agent " et d'utiliser à la place une chaîne d'agent Internet Explorer particulière. (voir figures 12 et 13).


Valeurs par défaut des requêtes Java ¶
Le composant Java Request Defaults vous permet de définir des valeurs par défaut pour les tests Java. Voir la requête Java .

Configuration de la connexion JDBC ¶

Paramètres ¶
Si vous voulez vraiment utiliser la mise en pool partagée (pourquoi ?), définissez le nombre maximal sur le même nombre que le nombre de threads pour vous assurer que les threads ne s'attendent pas les uns les autres.
La liste des requêtes de validation peut être configurée avec la propriété jdbc.config.check.query et sont par défaut :
- hsqldb
- sélectionnez 1 dans INFORMATION_SCHEMA.SYSTEM_USERS
- Oracle
- sélectionnez 1 parmi deux
- DB2
- sélectionnez 1 dans sysibm.sysdummy1
- MySQL ou MariaDB
- sélectionnez 1
- Microsoft SQL Server (pilote MS JDBC)
- sélectionnez 1
- PostgreSQLName
- sélectionnez 1
- Ingres
- sélectionnez 1
- Derby
- valeurs 1
- H2
- sélectionnez 1
- Oiseau de feu
- sélectionnez 1 dans la base de données rdb $
- Exasol
- sélectionnez 1
La liste des classes de pilotes jdbc préconfigurées peut être configurée avec la propriété jdbc.config.jdbc.driver.class et sont par défaut :
- hsqldb
- org.hsqldb.jdbc.JDBCDriver
- Oracle
- oracle.jdbc.OracleDriver
- DB2
- com.ibm.db2.jcc.DB2Driver
- MySQL
- com.mysql.jdbc.Driver
- Microsoft SQL Server (pilote MS JDBC)
- com.microsoft.sqlserver.jdbc.SQLServerDriver ou com.microsoft.jdbc.sqlserver.SQLServerDriver
- PostgreSQLName
- org.postgresql.Driver
- Ingres
- com.ingres.jdbc.IngresDriver
- Derby
- org.apache.derby.jdbc.ClientDriver
- H2
- org.h2.Driver
- Oiseau de feu
- org.firebirdsql.jdbc.FBDriver
- Derby apache
- org.apache.derby.jdbc.ClientDriver
- MariaDB
- org.mariadb.jdbc.Driver
- SQLiteName
- org.sqlite.JDBC
- Sybase AES
- net.sourceforge.jtds.jdbc.Driver
- Exasol
- com.exasol.jdbc.EXADriver
Des bases de données et des pilotes JDBC différents nécessitent des paramètres JDBC différents. L'URL de la base de données et la classe du pilote JDBC sont définies par le fournisseur de l'implémentation JDBC.
Certains paramètres possibles sont indiqués ci-dessous. Veuillez vérifier les détails exacts dans la documentation du pilote JDBC.
Si JMeter signale Aucun pilote approprié , cela peut signifier soit :
- La classe de pilote est introuvable. Dans ce cas, il y aura un message de journal tel que DataSourceElement : Impossible de charger le pilote : {classname} java.lang.ClassNotFoundException : {classname}
- La classe de pilote a été trouvée, mais la classe ne prend pas en charge la chaîne de connexion. Cela peut être dû à une erreur de syntaxe dans la chaîne de connexion ou à l'utilisation d'un nom de classe incorrect.
Si le serveur de base de données n'est pas en cours d'exécution ou n'est pas accessible, JMeter signalera une java.net.ConnectException .
Quelques exemples de bases de données et leurs paramètres sont donnés ci-dessous.
- MySQL
-
- Classe de pilote
- com.mysql.jdbc.Driver
- URL de la base de données
- jdbc:mysql://host[:port]/dbname
- PostgreSQLName
-
- Classe de pilote
- org.postgresql.Driver
- URL de la base de données
- jdbc:postgresql :{nombase}
- Oracle
-
- Classe de pilote
- oracle.jdbc.OracleDriver
- URL de la base de données
- jdbc:oracle:thin:@//host:port/service OR jdbc:oracle:thin:@(description=(address=(host={mc-name})(protocol=tcp)(port={port-no} ))(connect_data=(sid={sid})))
- Entrée (2006)
-
- Classe de pilote
- ingres.jdbc.IngresDriver
- URL de la base de données
- jdbc:ingres://host:port/db[;attr=value]
- Microsoft SQL Server (pilote MS JDBC)
-
- Classe de pilote
- com.microsoft.sqlserver.jdbc.SQLServerDriver
- URL de la base de données
- jdbc:sqlserver://host:port;DatabaseName=dbname
- Derby apache
-
- Classe de pilote
- org.apache.derby.jdbc.ClientDriver
- URL de la base de données
- jdbc:derby://server[:port]/databaseName[;URLAttributes=value[;…]]
- MariaDB
-
- Classe de pilote
- org.mariadb.jdbc.Driver
- URL de la base de données
- jdbc:mariadb://host[:port]/dbname[;URLAttributes=value[;…]]
- Exasol (voir aussi la documentation du pilote JDBC )
-
- Classe de pilote
- com.exasol.jdbc.EXADriver
- URL de la base de données
- jdbc:exa:host[:port][;schema=SCHEMA_NAME][;prop_x=value_x]
Configuration du magasin de clés ¶
L'élément Keystore Config vous permet de configurer la manière dont Keystore sera chargé et les clés qu'il utilisera. Ce composant est généralement utilisé dans les scénarios HTTPS où vous ne souhaitez pas prendre en compte l'initialisation du magasin de clés dans le temps de réponse.
Pour utiliser cet élément, vous devez d'abord configurer un Java Key Store avec les certificats clients que vous souhaitez tester, pour ce faire :
- Créez vos certificats soit avec l'utilitaire Java keytool soit via votre PKI
- Si elles sont créées par PKI, importez vos clés dans Java Key Store en les convertissant dans un format acceptable par JKS
- Ensuite, référencez le fichier keystore via les deux propriétés JVM (ou ajoutez-les dans system.properties ):
- -Djavax.net.ssl.keyStore=path_to_keystore
- -Djavax.net.ssl.keyStorePassword=password_of_keystore
Pour utiliser PKCS11 comme source du magasin, vous devez définir javax.net.ssl.keyStoreType sur PKCS11 et javax.net.ssl.keyStore sur NONE .

Paramètres ¶
- https.use.cached.ssl.context=false est défini dans jmeter.properties ou user.properties
- Vous utilisez l'implémentation HTTPClient 4 pour la requête HTTP
Élément de configuration de connexion ¶
L'élément de configuration de connexion vous permet d'ajouter ou de remplacer les paramètres de nom d'utilisateur et de mot de passe dans les échantillonneurs qui utilisent le nom d'utilisateur et le mot de passe dans le cadre de leur configuration.

Paramètres ¶
Paramètres par défaut des requêtes LDAP ¶
Le composant LDAP Request Defaults vous permet de définir des valeurs par défaut pour les tests LDAP. Voir la requête LDAP .

Paramètres par défaut des requêtes étendues LDAP ¶
Le composant LDAP Extended Request Defaults vous permet de définir des valeurs par défaut pour les tests LDAP étendus. Voir la demande étendue LDAP .

Configuration de l'échantillonneur TCP ¶
La configuration de l'échantillonneur TCP fournit des données par défaut pour l'échantillonneur TCP

Paramètres ¶
Variables définies par l'utilisateur ¶
L'élément Variables définies par l'utilisateur vous permet de définir un ensemble initial de variables , comme dans le plan de test .
Les UDV ne doivent pas être utilisées avec des fonctions qui génèrent des résultats différents à chaque fois qu'elles sont appelées. Seul le résultat du premier appel de la fonction sera enregistré dans la variable. Cependant, les UDV peuvent être utilisés avec des fonctions telles que __P() , par exemple :
HÔTE ${__P(hôte,hôte local)}
qui définirait la variable " HOST " pour avoir la valeur de la propriété JMeter " host ", par défaut à " localhost " si elle n'est pas définie.
Pour définir des variables lors d'une exécution de test, voir Paramètres utilisateur . Les UDV sont traitées dans l'ordre dans lequel elles apparaissent dans le plan, de haut en bas.
Pour plus de simplicité, il est suggéré que les UDV soient placés uniquement au début d'un groupe de threads (ou peut-être sous le plan de test lui-même).
Une fois que le plan de test et tous les UDV ont été traités, l'ensemble de variables résultant est copié dans chaque thread pour fournir l'ensemble initial de variables.
Si un élément d'exécution tel qu'un préprocesseur de paramètres utilisateur ou un extracteur d'expressions régulières définit une variable portant le même nom que l'une des variables UDV, cela remplacera la valeur initiale et tous les autres éléments de test du thread verront la mise à jour. évaluer.

Paramètres ¶
Variable aléatoire ¶
L'élément de configuration de variable aléatoire est utilisé pour générer des chaînes numériques aléatoires et les stocker dans une variable pour une utilisation ultérieure. C'est plus simple que d'utiliser des variables définies par l'utilisateur avec la fonction __Random() .
La variable de sortie est construite à l'aide du générateur de nombres aléatoires, puis le nombre résultant est formaté à l'aide de la chaîne de format. Le nombre est calculé à l'aide de la formule minimum+Random.nextInt(maximum-minimum+1) . Random.nextInt() nécessite un entier positif. Cela signifie que maximum-minimum - c'est-à-dire la plage - doit être inférieur à 2147483647 , mais les valeurs minimale et maximale peuvent être des valeurs longues tant que la plage est correcte.

Paramètres ¶
Compteur ¶
Permet à l'utilisateur de créer un compteur qui peut être référencé n'importe où dans le groupe de threads. La configuration du compteur permet à l'utilisateur de configurer un point de départ, un maximum et l'incrément. Le compteur bouclera du début au maximum, puis recommencera avec le début, continuant ainsi jusqu'à la fin du test.
Le compteur utilise un long pour stocker la valeur, donc la plage est de -2^63 à 2^63-1 .

Paramètres ¶
Élément de configuration simple ¶
L'élément de configuration simple vous permet d'ajouter ou de remplacer des valeurs arbitraires dans les échantillonneurs. Vous pouvez choisir le nom de la valeur et la valeur elle-même. Bien que certains utilisateurs aventureux puissent trouver une utilisation pour cet élément, il est principalement destiné aux développeurs en tant qu'interface graphique de base qu'ils peuvent utiliser lors du développement de nouveaux composants JMeter.

Paramètres ¶
Configuration source MongoDB (OBSOLÈTE) ¶
Vous pouvez ensuite accéder à l'objet com.mongodb.DB dans Beanshell ou JSR223 Test Elements via l'élément MongoDBHolder en utilisant ce code
importer com.mongodb.DB ;
importer org.apache.jmeter.protocol.mongodb.config.MongoDBHolder ;
DB db = MongoDBHolder.getDBFromSource("valeur de la propriété MongoDB Source",
"valeur de la propriété Nom de la base de données");
…

Paramètres ¶
Il y a un temps maximum pour continuer à réessayer, qui est de 15 secondes par défaut.
Cela peut être utile pour éviter que certaines exceptions ne soient levées lorsqu'un serveur est temporairement arrêté en bloquant les opérations.
Il peut également être utile de lisser la transition vers un nouveau nœud principal (afin qu'un nouveau nœud principal soit élu dans le délai de nouvelle tentative).
- pour un jeu de répliques, le pilote essaiera de se connecter à l'ancien nœud principal pendant ce temps, au lieu de basculer immédiatement vers le nouveau
- cela n'empêche pas l'exception d'être levée dans les opérations de lecture/écriture sur le socket, qui doivent être gérées par l'application.
Il est utilisé uniquement lors de l'établissement d'une nouvelle connexion Socket.connect(java.net.SocketAddress, int) La valeur
par défaut est 0 et signifie aucun délai d'attente.
La valeur par défaut est 0 , ce qui signifie qu'il faut utiliser la valeur par défaut de 15 secondes si autoConnectRetry est activé.
La valeur par défaut est 120 000 .
par défaut est 0 et signifie qu'il n'y a pas de délai d'attente.
par défaut est false .
Tous les autres threads obtiendront immédiatement une exception.
Par exemple, si connectionsPerHost vaut 10 et threadsAllowedToBlockForConnectionMultiplier vaut 5 , jusqu'à 50 threads peuvent attendre une connexion.
La valeur par défaut est 5 .
Si w , wtimeout , fsync ou j sont spécifiés, ce paramètre est ignoré.
La valeur par défaut est false .
La valeur par défaut est false .
La valeur par défaut est false .
La valeur par défaut est 0 .
La valeur par défaut est 0 .
Configuration de la connexion par boulon ¶

Paramètres ¶
18.5 Assertions ¶
Les assertions sont utilisées pour effectuer des vérifications supplémentaires sur les échantillonneurs et sont traitées après chaque échantillonneur dans la même portée. Pour vous assurer qu'une assertion est appliquée uniquement à un échantillonneur particulier, ajoutez-la en tant qu'enfant de l'échantillonneur.
Les assertions peuvent être appliquées à l'échantillon principal, aux sous-échantillons ou aux deux. La valeur par défaut consiste à appliquer l'assertion à l'échantillon principal uniquement. Si l'assertion prend en charge cette option, il y aura une entrée sur l'interface graphique qui ressemblera à ceci :


Si un sous-échantillonneur échoue et que l'échantillon principal réussit, l'échantillon principal sera défini sur le statut d'échec et un résultat d'assertion sera ajouté. Si l'option de variable JMeter est utilisée, elle est supposée se rapporter à l'échantillon principal, et tout échec sera appliqué à l'échantillon principal uniquement.
Assertion de réponse ¶
Le panneau de contrôle d'assertion de réponse vous permet d'ajouter des chaînes de modèle à comparer à divers champs de la demande ou de la réponse. Les chaînes de modèle sont :
- Contient , Correspond aux expressions régulières de style Perl5
- Equals , Substring : texte brut, sensible à la casse
Un résumé des caractères de correspondance de modèle peut être trouvé dans les expressions régulières ORO Perl5.
Vous pouvez également choisir si les chaînes doivent correspondre à l'intégralité de la réponse ou si la réponse ne doit contenir que le modèle. Vous pouvez attacher plusieurs assertions à n'importe quel contrôleur pour plus de flexibilité.
Notez que la chaîne de modèle ne doit pas inclure les délimiteurs englobants, c'est-à-dire utiliser Price: \d+ et non /Price: \d+/ .
Par défaut, le modèle est en mode multi-ligne, ce qui signifie que le méta-caractère " . " ne correspond pas à la nouvelle ligne. En mode multiligne, " ^ " et " $ " correspondent au début ou à la fin de n'importe quelle ligne n'importe où dans la chaîne - pas seulement au début et à la fin de la chaîne entière. Notez que \s correspond à la nouvelle ligne. Le cas est également significatif. Pour remplacer ces paramètres, on peut utiliser la syntaxe d'expression régulière étendue . Par exemple:
- (?je)
- ignorer la casse
- (?s)
- traiter la cible comme une seule ligne, c'est-à-dire " . " correspond à une nouvelle ligne
- (?est)
- les deux ci-dessus
- (?i) tarte aux pommes (?-i)
- correspond à « AppLe Pie », mais pas à « AppLe Pie »
- (?s)Pomme.+?Tarte
- correspond à Apple suivi de Pie , qui peut se trouver sur une ligne suivante.
- Pomme(?s).+?Tarte
- comme ci-dessus, mais il est probablement plus clair d'utiliser le (?s) au début.

Paramètres ¶
- Échantillon principal uniquement - ne s'applique qu'à l'échantillon principal
- Sous-échantillons uniquement - s'applique uniquement aux sous-échantillons
- Échantillon principal et sous-échantillons - s'applique aux deux.
- Nom de la variable JMeter à utiliser - l'assertion doit être appliquée au contenu de la variable nommée
- Réponse textuelle - le texte de la réponse du serveur, c'est-à-dire le corps, à l'exclusion de tout en-tête HTTP.
- Données de la requête - le texte de la requête envoyé au serveur, c'est-à-dire le corps, à l'exclusion des en-têtes HTTP.
- Code de réponse - par exemple 200
- Message de réponse - par exemple OK
- En- têtes de réponse , y compris les en-têtes Set-Cookie (le cas échéant)
- En-têtes de demande
- URL échantillonnée
- Document (texte) - le texte extrait de divers types de documents via Apache Tika (voir la section Afficher l'arborescence des résultats de l' affichage du document).
Le succès global de l'échantillon est déterminé en combinant le résultat de l'assertion avec le statut de réponse existant. Lorsque la case Ignorer le statut est cochée, le statut de la réponse est forcé à réussir avant d'évaluer l'assertion.
Les réponses HTTP avec des statuts dans les plages 4xx et 5xx sont normalement considérées comme ayant échoué. La case à cocher " Ignorer le statut " peut être utilisée pour définir le statut réussi avant d'effectuer d'autres vérifications. Notez que cela aura pour effet d'effacer tous les échecs d'assertion précédents, alors assurez-vous que cela n'est défini que sur la première assertion.- Contient - vrai si le texte contient le modèle d'expression régulière
- Matches - true si tout le texte correspond au modèle d'expression régulière
- Égal à - vrai si tout le texte est égal à la chaîne de modèle (sensible à la casse)
- Sous -chaîne - vrai si le texte contient la chaîne de modèle (sensible à la casse)
Le motif est une expression régulière de style Perl5, mais sans les parenthèses.




Assertion de durée ¶
L'assertion de durée teste que chaque réponse a été reçue dans un laps de temps donné. Toute réponse qui prend plus de temps que le nombre de millisecondes donné (spécifié par l'utilisateur) est marquée comme une réponse ayant échoué.

Paramètres ¶
Assertion de taille ¶
L'assertion de taille teste que chaque réponse contient le bon nombre d'octets. Vous pouvez spécifier que la taille soit égale, supérieure, inférieure ou différente d'un nombre d'octets donné.

Paramètres ¶
- Échantillon principal uniquement - l'assertion ne s'applique qu'à l'échantillon principal
- Sous-échantillons uniquement - l'assertion ne s'applique qu'aux sous-échantillons
- Échantillon principal et sous-échantillons - l'assertion s'applique aux deux.
- Nom de la variable JMeter à utiliser - l'assertion doit être appliquée au contenu de la variable nommée
Assertion XML ¶
L'assertion XML vérifie que les données de réponse consistent en un document XML formellement correct. Il ne valide pas le XML basé sur une DTD ou un schéma et n'effectue aucune autre validation.

Paramètres ¶
Assertion BeanShell ¶
L'assertion BeanShell permet à l'utilisateur d'effectuer une vérification d'assertion à l'aide d'un script BeanShell.
Pour plus de détails sur l'utilisation de BeanShell, veuillez consulter le site Web de BeanShell.
Notez qu'un interpréteur différent est utilisé pour chaque occurrence indépendante de l'assertion dans chaque thread d'un script de test, mais le même interpréteur est utilisé pour les invocations suivantes. Cela signifie que les variables persistent à travers les appels à l'assertion.
Toutes les assertions sont appelées à partir du même thread que l'échantillonneur.
Si la propriété " beanshell.assertion.init " est définie, elle est transmise à l'interpréteur en tant que nom d'un fichier sourcé. Cela peut être utilisé pour définir des méthodes et des variables communes. Il existe un exemple de fichier init dans le répertoire bin : BeanShellAssertion.bshrc
L'élément de test prend en charge les méthodes ThreadListener et TestListener . Ceux-ci doivent être définis dans le fichier d'initialisation. Voir le fichier BeanShellListeners.bshrc pour des exemples de définitions.

Paramètres ¶
- Paramètres - chaîne contenant les paramètres comme une seule variable
- bsh.args - Tableau de chaînes contenant des paramètres, divisés en espaces blancs
Il existe un exemple de script que vous pouvez essayer.
Avant d'invoquer le script, certaines variables sont configurées dans l'interpréteur BeanShell. Sauf indication contraire, ce sont des chaînes :
- log - l' objet enregistreur . (par exemple) log.warn("Message"[,Jetable])
- SampleResult , prev - l' objet SampleResult ; lire écrire
- Réponse - l'objet de réponse ; lire écrire
- Échec - booléen ; lire écrire; utilisé pour définir le statut Assertion
- Message d'échec - Chaîne ; lire écrire; utilisé pour définir le message d'assertion
- ResponseData - le corps de la réponse (octet [])
- ResponseCode - par exemple 200
- ResponseMessage - par exemple OK
- ResponseHeaders - contient les en-têtes HTTP
- RequestHeaders - contient les en-têtes HTTP envoyés au serveur
- ÉchantillonÉtiquette
- SamplerData - données envoyées au serveur
- ctx - JMeterContext
-
vars - JMeterVariables - par exemple
vars.get("VAR1"); vars.put("VAR2","valeur"); vars.putObject("OBJ1",nouvel objet()); -
accessoires - JMeterProperties (classe java.util.Properties ) - par exemple
props.get("START.HMS"); props.put("PROP1","1234");
Les méthodes suivantes de l'objet Response peuvent être utiles :
- setStopThread(booléen)
- setStopTest(booléen)
- Chaîne getSampleLabel()
- setSampleLabel(String)
Assertion MD5Hex ¶
L'assertion MD5Hex permet à l'utilisateur de vérifier le hachage MD5 des données de réponse.

Paramètres ¶
Assertion HTML ¶
L'assertion HTML permet à l'utilisateur de vérifier la syntaxe HTML des données de réponse à l'aide de JTidy.

Paramètres ¶
Assertion XPath ¶
L'assertion XPath teste la bonne formation d'un document, a la possibilité de valider par rapport à une DTD ou de placer le document via JTidy et de tester un XPath. Si ce XPath existe, l'assertion est vraie. L'utilisation de " / " correspondra à tout document bien formé et constitue l'expression XPath par défaut. L'assertion prend également en charge les expressions booléennes, telles que " count(//*error)=2 ". Voir http://www.w3.org/TR/xpath pour plus d'informations sur XPath.
Quelques exemples d'expressions :- //title[text()='Text to match'] - correspond à <title>Text to match</title> n'importe où dans la réponse
- /title[text()='Text to match'] - correspond à <title>Text to match</title> au niveau racine dans la réponse

Paramètres ¶
Pour contourner les limitations d'espace de noms de l'analyseur Xalan XPath (implémentation sur laquelle JMeter est basé), vous devez :
- fournissez un fichier de propriétés (si par exemple votre fichier s'appelle namespaces.properties ) qui contient des mappages pour les préfixes d'espace de noms :
prefix1=http\://foo.apache.org prefix2=http\://toto.apache.org …
- référencez ce fichier dans le fichier user.properties en utilisant la propriété :
xpath.namespace.config=espaces de noms.properties
Assertion XPath2 ¶
L'assertion XPath2 teste la bonne formation d'un document. L'utilisation de " / " correspondra à tout document bien formé et constitue l'expression XPath2 par défaut. L'assertion prend également en charge les expressions booléennes, telles que " count(//*error)=2 ".
Quelques exemples d'expressions :- //title[text()='Text to match'] - correspond à <title>Text to match</title> n'importe où dans la réponse
- /title[text()='Text to match'] - correspond à <title>Text to match</title> au niveau racine dans la réponse
Paramètres ¶
Assertion de schéma XML ¶
L'assertion de schéma XML permet à l'utilisateur de valider une réponse par rapport à un schéma XML.

Paramètres ¶
Assertion JSR223 ¶
L'assertion JSR223 permet d'utiliser le code de script JSR223 pour vérifier l'état de l'échantillon précédent.
Paramètres ¶
- Paramètres - chaîne contenant les paramètres comme une seule variable
- args - Tableau de chaînes contenant des paramètres, divisés en espaces blancs
Les variables suivantes sont configurées pour être utilisées par le script :
- log - ( Logger ) - peut être utilisé pour écrire dans le fichier journal
- Étiquette - l'étiquette de chaîne
- Nom de fichier - le nom du fichier de script (le cas échéant)
- Paramètres - les paramètres (sous forme de chaîne)
- args - les paramètres sous la forme d'un tableau String (divisé en espaces)
- ctx - ( JMeterContext ) - donne accès au contexte
-
vars - ( JMeterVariables ) - donne un accès en lecture/écriture aux variables :
vars.get(clé); vars.put(clé,val); vars.putObject("OBJ1",nouvel objet()); vars.getObject("OBJ2"); -
accessoires - (JMeterProperties - classe java.util.Properties ) - par exemple
props.get("START.HMS"); props.put("PROP1","1234"); - SampleResult , prev - ( SampleResult ) - donne accès au SampleResult précédent (le cas échéant)
- sampler - ( Sampler ) - donne accès au sampler courant
- OUT - System.out - par exemple OUT.println("message")
- AssertionResult - ( AssertionResult ) - le résultat de l'assertion
Le script peut vérifier divers aspects du SampleResult . Si une erreur est détectée, le script doit utiliser AssertionResult.setFailureMessage("message") et AssertionResult.setFailure(true) .
Pour plus de détails sur toutes les méthodes disponibles sur chacune des variables ci-dessus, veuillez consulter la Javadoc
Comparer l'assertion ¶

Paramètres ¶
Assertion SMIME ¶
- bcmail-xxx.jar (SMIME/CMS de BouncyCastle)
- bcprov-xxx.jar (Fournisseur BouncyCastle)
Si vous utilisez l' échantillonneur de lecteur de courrier , assurez-vous de sélectionner « Stocker le message à l'aide de MIME (brut) », sinon l'assertion ne pourra pas traiter le message correctement.

Paramètres ¶
Assertion JSON ¶
Ce composant permet d'effectuer des validations de documents JSON. Tout d'abord, il analysera le JSON et échouera si les données ne sont pas JSON. Deuxièmement, il recherchera le chemin spécifié, en utilisant la syntaxe de Jayway JsonPath 1.2.0 . Si le chemin n'est pas trouvé, il échouera. Troisièmement, si le chemin JSON a été trouvé dans le document et qu'une validation par rapport à la valeur attendue a été demandée, il effectuera la validation. Pour la valeur nulle , il y a une case à cocher spéciale dans l'interface graphique. Notez que si le chemin renvoie l'objet tableau, il sera itéré et si la valeur attendue est trouvée, l'assertion réussira. Pour valider un tableau vide, utilisez []chaîne de caractères. De plus, si patch renverra un objet dictionnaire, il sera converti en chaîne avant la comparaison.

Paramètres ¶
Assertion JSON JMESPath ¶
Ce composant vous permet d'effectuer une assertion sur le contenu des documents JSON à l'aide de JMESPath . Tout d'abord, il analysera le JSON et échouera si les données ne sont pas JSON.
Deuxièmement, il recherchera le chemin spécifié, en utilisant la syntaxe JMESPath.
Si le chemin n'est pas trouvé, il échouera.
Troisièmement, si le chemin JMES a été trouvé dans le document et qu'une validation par rapport à la valeur attendue a été demandée, il effectuera cette vérification supplémentaire. Si vous souhaitez vérifier la nullité, utilisez la case à cocher Expect null .
Notez que le chemin ne peut pas être nul car l'expression JMESPath ne sera pas compilée et une erreur se produira. Même si vous attendez une réponse vide ou nulle, vous devez mettre une expression JMESPath valide.

Paramètres ¶
18.6 Minuteries ¶
Vous pouvez appliquer un facteur de multiplication sur les délais de veille calculés par Random timer en définissant la propriété timer.factor=float number où float number est un nombre décimal positif.
JMeter multipliera ce facteur par le délai de veille calculé. Cette fonctionnalité peut être utilisée par :
Les minuteries ne sont traitées qu'en conjonction avec un échantillonneur. Une minuterie qui n'est pas dans la même portée qu'un échantillonneur ne sera pas traitée du tout.
Pour appliquer une minuterie à un échantillonneur unique, ajoutez la minuterie en tant qu'élément enfant de l'échantillonneur. La minuterie sera appliquée avant l'exécution de l'échantillonneur. Pour appliquer une minuterie après un échantillonneur, ajoutez-la à l'échantillonneur suivant ou ajoutez-la en tant qu'enfant d'un échantillonneur d'action de contrôle de flux .
Minuterie constante ¶
Si vous souhaitez que chaque thread s'interrompe pendant la même durée entre les requêtes, utilisez ce minuteur.

Paramètres ¶
Temporisateur aléatoire gaussien ¶
Ce temporisateur met en pause chaque demande de thread pendant une durée aléatoire, la plupart des intervalles de temps se produisant près d'une valeur particulière. Le retard total est la somme de la valeur distribuée gaussienne (avec une moyenne de 0,0 et un écart type de 1,0 ) multipliée par la valeur d'écart que vous spécifiez et la valeur de décalage. Une autre façon de l'expliquer, dans Gaussian Random Timer, la variation autour d'un décalage constant a une distribution de courbe gaussienne.

Paramètres ¶
Minuterie aléatoire uniforme ¶
Ce temporisateur met en pause chaque demande de thread pendant une durée aléatoire, chaque intervalle de temps ayant la même probabilité de se produire. Le retard total est la somme de la valeur aléatoire et de la valeur de décalage.

Paramètres ¶
Minuterie à débit constant ¶
Cette minuterie introduit des pauses variables, calculées pour maintenir le débit total (en termes d'échantillons par minute) aussi proche que possible d'un chiffre donné. Bien sûr, le débit sera plus faible si le serveur n'est pas capable de le gérer, ou si d'autres temporisateurs ou éléments de test chronophages l'en empêchent.
NB bien que le temporisateur soit appelé temporisateur à débit constant, la valeur du débit n'a pas besoin d'être constante. Il peut être défini en termes d'appel de variable ou de fonction, et la valeur peut être modifiée au cours d'un test. La valeur peut être modifiée de différentes manières :
- à l'aide d'une variable compteur
- en utilisant une fonction __jexl3 , __groovy pour fournir une valeur changeante
- utiliser le serveur BeanShell distant pour modifier une propriété JMeter
Voir Meilleures pratiques pour plus de détails.

Paramètres ¶
- ce thread uniquement - chaque thread tentera de maintenir le débit cible. Le débit global sera proportionnel au nombre de threads actifs.
- tous les threads actifs dans le groupe de threads actuel - le débit cible est divisé entre tous les threads actifs du groupe. Chaque thread sera retardé selon les besoins, en fonction de la date de sa dernière exécution.
- tous les threads actifs - le débit cible est divisé entre tous les threads actifs dans tous les groupes de threads. Chaque thread sera retardé selon les besoins, en fonction de la date de sa dernière exécution. Dans ce cas, chacun des autres groupes de threads aura besoin d'une minuterie à débit constant avec les mêmes paramètres.
- tous les threads actifs dans le groupe de threads actuel (partagé) - comme ci-dessus, mais chaque thread est retardé en fonction de la dernière exécution d'un thread du groupe.
- tous les threads actifs (partagés) - comme ci-dessus ; chaque thread est retardé en fonction de la dernière exécution d'un thread.
Les algorithmes partagés et non partagés visent tous deux à générer le débit souhaité et produiront des résultats similaires.
L'algorithme partagé devrait générer un taux de transaction global plus précis.
L'algorithme non partagé devrait générer une répartition plus uniforme des transactions entre les threads.
Minuteur de débit précis ¶
Cette minuterie introduit des pauses variables, calculées pour maintenir le débit total (par exemple en termes d'échantillons par minute) aussi près que possible d'un chiffre donné. Bien sûr, le débit sera plus faible si le serveur n'est pas capable de le gérer, ou si d'autres minuteries, ou s'il n'y a pas assez de threads, ou des éléments de test chronophages l'en empêchent.
Bien que le minuteur soit appelé Precise Throughput Timer, il ne vise pas à produire exactement le même nombre d'échantillons sur des intervalles d'une seconde pendant le test.
La minuterie fonctionne mieux pour des débits inférieurs à 36 000 requêtes/heure, mais votre kilométrage peut varier (voir la section de surveillance ci-dessous si vos objectifs sont très différents).
Meilleur emplacement d'un temporisateur de débit précis dans un plan de test
Comme vous le savez peut-être, les temporisateurs sont hérités par tous les frères et leurs éléments enfants. C'est pourquoi l'un des meilleurs endroits pour Precise Throughput Timer est sous le premier élément d'une boucle de test. Par exemple, vous pouvez ajouter un échantillonneur factice au début et placer la minuterie sous cet échantillonneur factice.
Calendrier produit
Precise Throughput Timer modélise l'horaire des arrivées de Poisson . Ce calendrier se produit souvent dans la vie réelle, il est donc logique de l'utiliser pour les tests de charge. Par exemple, cela pourrait naturellement générer des échantillons proches les uns des autres, ce qui pourrait révéler des problèmes de concurrence. Même si vous parvenez à générer des arrivées de Poisson avec Poisson Random Timer , il serait sensible aux problèmes répertoriés ci-dessous. Par exemple, les vraies arrivées de Poisson peuvent avoir une pause indéfiniment longue, ce qui n'est pas pratique pour les tests de charge. Par exemple, les arrivées de Poisson "régulières" avec un taux de 1 par seconde peuvent se retrouver avec 50 échantillons sur un test de 60 secondes.
Constant Throughput Timer converge vers le débit spécifié, mais il a tendance à produire des échantillons à intervalles réguliers.
Montée en puissance et pic de démarrage
Vous pouvez utiliser une "accélération" ou des approches similaires pour éviter un pic au début du test. Par exemple, si vous configurez le groupe de threads pour qu'il ait 100 threads et que vous réglez la période de montée en puissance sur 0 (ou sur un petit nombre), tous les threads démarreront en même temps et cela produira un pic indésirable de la charge . De plus, si vous définissez une période de montée en puissance trop élevée, il se peut que « trop peu » de threads soient disponibles au tout début pour atteindre la charge requise.
Precise Throughput Timer planifie les exécutions de manière aléatoire, de sorte qu'il peut être utilisé pour générer une charge constante, et il est recommandé de définir à la fois la période de montée en puissance et le délai sur 0 .
Plusieurs groupes de threads commençant en même temps
Une variante du problème de montée en puissance peut apparaître lorsque le plan de test inclut plusieurs groupes de threads . Pour atténuer ce problème, on ajoute généralement un délai "aléatoire" à chaque groupe de threads afin que les threads démarrent à des moments différents.
Precise Throughput Timer évite ce problème car il planifie les exécutions de manière aléatoire. Vous n'avez pas besoin d'ajouter des délais aléatoires supplémentaires pour atténuer le pic de démarrage
Nombre d'itérations par heure
L'une des exigences de base est d'émettre N échantillons par M minutes. Soit 60 itérations par heure. Les clients professionnels ne comprendraient pas si vous rapportiez les résultats des tests de charge avec 57 exécutions "simplement parce que le hasard était aléatoire". Afin de générer 60 itérations par heure, vous devez configurer comme suit (d'autres paramètres peuvent être laissés avec leurs valeurs par défaut)
- Débit cible (échantillons) : 60
- Période de débit (secondes) : 3600
- Durée du test (secondes) : 3600
Les deux premières options définissent le débit. Même si 60/3600, 30/1800 et 120/7200 représentent exactement le même niveau de charge, choisissez celui qui représente le mieux les besoins de l'entreprise. Par exemple, si l'exigence est de tester "60 échantillons par heure", alors réglez 60/3600. Si l'exigence est de tester "1 échantillon par minute", alors réglez 1/60.
La durée du test (secondes) est là pour que la minuterie assure le nombre exact d'échantillons pour une durée de test donnée. Precise Throughput Timer crée un calendrier pour les échantillons au démarrage du test. Par exemple, si vous souhaitez effectuer un test de 5 minutes avec un débit de 60 par heure, vous devez définir la durée du test (secondes) sur 300. Cela permet de configurer le débit de manière conviviale. Remarque : La durée du test (secondes) ne limite pas la durée du test. C'est juste un indice pour la minuterie.
Nombre de discussions et temps de réflexion
L'un des pièges courants consiste à ajuster le nombre de threads et les temps de réflexion afin d'obtenir le débit souhaité. Même si cela peut fonctionner, cette approche entraîne beaucoup de temps passé sur les tests. Il peut être nécessaire d'ajuster à nouveau les threads et les délais lors de l'arrivée d'une nouvelle version de l'application.
La minuterie de débit précise permet de définir un objectif de débit et d'y aller, quelle que soit la performance de l'application. Pour ce faire, Precise Throughput Timer crée un calendrier au démarrage du test, puis il utilise ce calendrier pour libérer les threads. Le principal moteur des temps de réflexion et du nombre de threads devrait être les besoins de l'entreprise, et non le désir de faire correspondre le débit d'une manière ou d'une autre.
Par exemple, si votre application est utilisée par des ingénieurs de support dans un centre d'appels. Supposons qu'il y ait 2 ingénieurs dans le centre d'appels et que le débit cible soit de 1 par minute. Supposons qu'il faille 4 minutes à l'ingénieur pour lire et réviser la page Web. Dans ce cas, vous devez définir 2 threads dans le groupe, utiliser 4 minutes pour les délais de réflexion et spécifier 1 par minute dans Precise Throughput Timer . Bien sûr, cela donnerait quelque chose autour de 2 échantillons/4 minutes = 0,5 par minute et le résultat d'un tel test signifie "vous avez besoin de plus d'ingénieurs de support dans un centre d'appels" ou "vous devez réduire le temps qu'il faut à un ingénieur pour accomplir une tâche ".
Tester des taux faibles et des tests répétables
Tester à faible cadence (par exemple 60 par heure) nécessite de connaître le profil de test souhaité. Par exemple, si vous devez injecter de la charge à intervalles réguliers (par exemple, 60 secondes entre les deux), vous feriez mieux d'utiliser Constant Throughput Timer . Cependant, si vous avez besoin d'un calendrier aléatoire (par exemple pour modéliser de vrais utilisateurs qui exécutent des rapports), alors Precise Throughput Timer est votre ami.
Lors de la comparaison des résultats de plusieurs tests de charge, il est utile de pouvoir répéter exactement le même profil de test. Par exemple, si l'action X (par exemple "Profit Report") est invoquée après 5 minutes de démarrage du test, alors il serait bien de reproduire ce modèle pour les exécutions de test suivantes. La réplication du même modèle de charge simplifie l'analyse des résultats de test (par exemple, le graphique CPU%).
La valeur de départ aléatoire (passage de 0 à aléatoire) permet de contrôler la valeur de départ utilisée par Precise Throughput Timer . Par défaut, il est initialisé avec 0 et cela signifie qu'une graine aléatoire est utilisée pour chaque exécution de test. Si vous avez besoin d'un modèle de charge reproductible, modifiez la valeur de départ aléatoire afin d'obtenir une valeur aléatoire. Le conseil général est d'utiliser une graine non nulle, et "0 par défaut" est une limite d'implémentation.
Remarque : lors de l'utilisation de plusieurs groupes de threads avec les mêmes débits et la même graine non nulle, cela peut entraîner un déclenchement indésirable des échantillons en même temps.
Tester des cadences élevées et/ou de longues durées de test
Precise Throughput Timer génère le programme et le garde en mémoire. Dans la plupart des cas, cela ne devrait pas poser de problème, cependant, rappelez-vous que vous pourriez vouloir garder le calendrier plus court que 1'000'000 d'échantillons. Il faut environ 200 ms pour générer un programme pour 1 000 000 d'échantillons, et le programme consomme 8 mégaoctets dans le tas. Le programme pour 10 millions d'entrées prend 1 à 2 secondes à construire et consomme 80 mégaoctets dans le tas.
Par exemple, si vous souhaitez effectuer un test de 2 semaines avec un taux de 5 000 par heure, vous souhaitez probablement avoir exactement 5 000 échantillons pour chaque heure. Vous pouvez définir la propriété Durée du test (secondes) de la minuterie de la minuterie sur 1 heure. Ensuite, le minuteur créerait un programme de 5 000 échantillons pour une heure, et lorsque le programme est épuisé, le minuteur générerait un programme pour l'heure suivante.
Dans le même temps, vous pouvez définir la durée du test (secondes) sur 2 semaines, et la minuterie générera un calendrier avec 168'000 échantillons = 2 semaines * 5'000 échantillons/heure = 2*7*24*500 . Le programme prendrait environ 30 ms à générer et consommerait un peu plus de 1 mégaoctet.
Charge éclatée
Il peut y avoir un cas où tous les échantillons doivent venir par paires, triplets, etc. Certains cas peuvent être résolus via Synchronizing Timer , cependant Precise Throughput Timer a un moyen natif d'émettre des demandes dans des packs. Ce comportement est désactivé par défaut, et il est contrôlé avec les paramètres "Départs groupés"
- Nombre de threads dans le lot (threads) . Spécifie le nombre d'échantillons dans un lot. Notez que le nombre total d'échantillons sera toujours conforme au débit cible
- Délai entre les threads dans le lot (ms) . Par exemple, s'il est défini sur 42 et que la taille du lot est de 3, les threads partiront à x, x + 42 ms, x + 84 ms
Taux de charge variable
Même si les valeurs de propriété (par exemple, le débit) peuvent être définies via des expressions, il est recommandé de conserver plus ou moins la même valeur tout au long du test, car il faut du temps pour recalculer le nouveau calendrier pour adapter les nouvelles valeurs.
Surveillance
Lors de la génération du prochain programme, Precise Throughput Timer enregistre un message sur jmeter.log : 2018-01-04 17:34:03,635 INFO oajtConstantPoissonProcessGenerator : 21 synchronisations générées (... 20 requis, taux 1,0, durée 20, lim exacte 20 000, i21) en 0 ms. First 15 events will be fired at: 1.1869653574244292 (+1.1869653574244292), 1.4691340403043207 (+0.2821686828798915), 3.638151706179226 (+2.169017665874905), 3.836357090410566 (+0.19820538423134026), 4.709330071408575 (+0.8729729809980085), 5.61330076999953 (+0.903970698590955), ... Cela montre que la génération de planification a pris 0 ms et affiche des horodatages absolus en secondes. Dans le cas ci-dessus, le taux a été défini sur 1 par seconde et les horodatages réels sont devenus 1,2 s, 1,5 s, 3,6 s, 3,8 s, 4,7 s, etc.

Paramètres ¶
Minuterie de synchronisation ¶
Le but du SyncTimer est de bloquer les threads jusqu'à ce qu'un nombre X de threads aient été bloqués, puis ils sont tous libérés en même temps. Un SyncTimer peut ainsi créer de grandes charges instantanées à différents points du plan de test.

Paramètres ¶
Minuterie BeanShell ¶
Le minuteur BeanShell peut être utilisé pour générer un délai.
Pour plus de détails sur l'utilisation de BeanShell, veuillez consulter le site Web de BeanShell.
L'élément de test prend en charge les méthodes ThreadListener et TestListener . Ceux-ci doivent être définis dans le fichier d'initialisation. Voir le fichier BeanShellListeners.bshrc pour des exemples de définitions.

Paramètres ¶
- Paramètres - chaîne contenant les paramètres comme une seule variable
- bsh.args - Tableau de chaînes contenant des paramètres, divisés en espaces blancs
Avant d'invoquer le script, certaines variables sont configurées dans l'interpréteur BeanShell :
- log - ( Logger ) - peut être utilisé pour écrire dans le fichier journal
- ctx - ( JMeterContext ) - donne accès au contexte
-
vars - ( JMeterVariables ) - donne un accès en lecture/écriture aux variables :
vars.get(clé); vars.put(clé,val); vars.putObject("OBJ1",nouvel objet()); - props - (JMeterProperties - classe java.util.Properties) - par exemple props.get("START.HMS"); props.put("PROP1","1234");
- prev - ( SampleResult ) - donne accès au précédent SampleResult (le cas échéant)
Pour plus de détails sur toutes les méthodes disponibles sur chacune des variables ci-dessus, veuillez consulter la Javadoc
Si la propriété beanshell.timer.init est définie, elle est utilisée pour charger un fichier d'initialisation, qui peut être utilisé pour définir des méthodes, etc. à utiliser dans le script BeanShell.
Minuterie JSR223 ¶
Le temporisateur JSR223 peut être utilisé pour générer un délai à l'aide d'un langage de script JSR223,
Paramètres ¶
- Paramètres - chaîne contenant les paramètres comme une seule variable
- args - Tableau de chaînes contenant des paramètres, divisés en espaces blancs
Avant d'invoquer le script, certaines variables sont configurées dans l'interpréteur de script :
- log - ( Logger ) - peut être utilisé pour écrire dans le fichier journal
- ctx - ( JMeterContext ) - donne accès au contexte
-
vars - ( JMeterVariables ) - donne un accès en lecture/écriture aux variables :
vars.get(clé); vars.put(clé,val); vars.putObject("OBJ1",nouvel objet()); - props - (JMeterProperties - classe java.util.Properties) - par exemple props.get("START.HMS"); props.put("PROP1","1234");
- sampler - ( Sampler ) - le Sampler actuel
- Étiquette - le nom de la minuterie
- FileName - le nom du fichier (le cas échéant)
- OUT - System.out
Pour plus de détails sur toutes les méthodes disponibles sur chacune des variables ci-dessus, veuillez consulter la Javadoc
Minuterie aléatoire de Poisson ¶
Ce temporisateur met en pause chaque demande de thread pendant une durée aléatoire, la plupart des intervalles de temps se produisant près d'une valeur particulière. Le retard total est la somme de la valeur distribuée de Poisson et de la valeur de décalage.
Remarque : si vous souhaitez modéliser les arrivées de Poisson, envisagez plutôt d'utiliser Precise Throughput Timer .

Paramètres ¶
18.7 Préprocesseurs ¶
Les préprocesseurs sont utilisés pour modifier les échantillonneurs dans leur portée.
Analyseur de lien HTML ¶
Ce modificateur analyse la réponse HTML du serveur et extrait les liens et les formulaires. Un échantillon de test d'URL qui passe par ce modificateur sera examiné pour voir s'il "correspond" à l'un des liens ou formulaires extraits de la réponse immédiatement précédente. Il remplacerait ensuite les valeurs de l'échantillon de test d'URL par les valeurs appropriées du lien ou du formulaire correspondant. Les expressions régulières de type Perl sont utilisées pour trouver des correspondances.

Prenons un exemple simple : disons que vous vouliez que JMeter "se déplace" sur votre site, en cliquant lien après lien analysé à partir du code HTML renvoyé par votre serveur (ce n'est pas vraiment la chose la plus utile à faire, mais c'est un bon exemple) . Vous créeriez un Simple Controller et y ajouteriez le "HTML Link Parser". Ensuite, créez une requête HTTP et définissez le domaine sur " .* ", ainsi que le chemin. Cela entraînera la correspondance de votre échantillon de test avec tout lien trouvé sur les pages renvoyées. Si vous souhaitez limiter le spidering à un domaine particulier, modifiez la valeur du domaine pour celle que vous souhaitez. Ensuite, seuls les liens vers ce domaine seront suivis.
Un exemple plus utile : étant donné une application de sondage Web, vous pouvez avoir une page avec plusieurs options de sondage sous forme de boutons radio à sélectionner par l'utilisateur. Disons que les valeurs des options de sondage sont très dynamiques - peut-être générées par l'utilisateur. Si vous vouliez que JMeter teste le sondage, vous pouvez soit créer des échantillons de test avec des valeurs codées en dur choisies, soit laisser l'analyseur de lien HTML analyser le formulaire et insérer une option de sondage aléatoire dans votre échantillon de test d'URL. Pour ce faire, suivez l'exemple ci-dessus, sauf que lors de la configuration des options d'URL de votre contrôleur Web Test, veillez à choisir " POST " comme méthode. Mettez des valeurs codées en dur pour le domaine , le chemin et tous les paramètres de formulaire supplémentaires. Ensuite, pour le paramètre de bouton radio réel, mettez le nom (disons-le 'poll_choice "), puis " .* " pour la valeur de ce paramètre. Lorsque le modificateur examine cet exemple de test d'URL, il constate qu'il "correspond" au formulaire de sondage (et qu'il ne doit correspondre à aucun autre formulaire, étant donné que vous avez spécifié tous les autres aspects de l'échantillon de test d'URL), et il remplacera vos paramètres de formulaire par les paramètres correspondants du formulaire. Puisque l'expression régulière " .* " correspondra à n'importe quoi, le modificateur aura probablement une liste de boutons radio parmi lesquels choisir. Il choisira au hasard et remplacera la valeur dans votre échantillon de test d'URL. À chaque test, une nouvelle valeur aléatoire sera choisie.

Modificateur de réécriture d'URL HTTP ¶
Ce modificateur fonctionne de la même manière que l'analyseur de liens HTML, sauf qu'il a un objectif spécifique pour lequel il est plus facile à utiliser que l'analyseur de liens HTML et plus efficace. Pour les applications Web qui utilisent la réécriture d'URL pour stocker les identifiants de session au lieu des cookies, cet élément peut être attaché au niveau ThreadGroup, un peu comme HTTP Cookie Manager . Donnez-lui simplement le nom du paramètre d'identifiant de session, et il le trouvera sur la page et ajoutera l'argument à chaque requête de ce ThreadGroup.
Alternativement, ce modificateur peut être attaché à des requêtes sélectionnées et il ne les modifiera qu'à elles seules. Les utilisateurs intelligents détermineront même que ce modificateur peut être utilisé pour saisir des valeurs qui échappent à l' analyseur de liens HTML .

Paramètres ¶
Paramètres utilisateur ¶
Permet à l'utilisateur de spécifier des valeurs pour les variables utilisateur spécifiques aux threads individuels.
Les variables utilisateur peuvent également être spécifiées dans le plan de test, mais pas spécifiques à des threads individuels. Ce panneau vous permet de spécifier une série de valeurs pour n'importe quelle variable utilisateur. Pour chaque thread, la variable se verra attribuer l'une des valeurs de la série dans l'ordre. S'il y a plus de threads que de valeurs, les valeurs sont réutilisées. Par exemple, cela peut être utilisé pour attribuer un identifiant d'utilisateur distinct à utiliser par chaque thread. Les variables utilisateur peuvent être référencées dans n'importe quel champ de n'importe quel composant JMeter.
La variable est spécifiée en cliquant sur le bouton Ajouter une variable en bas du panneau et en remplissant le nom de la variable dans la colonne ' Nom : '. Pour ajouter une nouvelle valeur à la série, cliquez sur le bouton ' Ajouter un utilisateur ' et remplissez la valeur souhaitée dans la colonne nouvellement ajoutée.
Les valeurs sont accessibles dans n'importe quel composant de test du même groupe de threads, en utilisant la syntaxe de la fonction : ${variable} .
Voir aussi l' élément CSV Data Set Config , qui est plus adapté à un grand nombre de paramètres

Paramètres ¶
Préprocesseur BeanShell ¶
Le préprocesseur BeanShell permet d'appliquer du code arbitraire avant de prélever un échantillon.
Pour plus de détails sur l'utilisation de BeanShell, veuillez consulter le site Web de BeanShell.
L'élément de test prend en charge les méthodes ThreadListener et TestListener . Ceux-ci doivent être définis dans le fichier d'initialisation. Voir le fichier BeanShellListeners.bshrc pour des exemples de définitions.

Paramètres ¶
- Paramètres - chaîne contenant les paramètres comme une seule variable
- bsh.args - Tableau de chaînes contenant des paramètres, divisés en espaces blancs
Avant d'invoquer le script, certaines variables sont configurées dans l'interpréteur BeanShell :
- log - ( Logger ) - peut être utilisé pour écrire dans le fichier journal
- ctx - ( JMeterContext ) - donne accès au contexte
-
vars - ( JMeterVariables ) - donne un accès en lecture/écriture aux variables :
vars.get(clé); vars.put(clé,val); vars.putObject("OBJ1",nouvel objet()); - props - (JMeterProperties - classe java.util.Properties) - par exemple props.get("START.HMS"); props.put("PROP1","1234");
- prev - ( SampleResult ) - donne accès au précédent SampleResult (le cas échéant)
- sampler - ( Sampler )- donne accès au sampler courant
Pour plus de détails sur toutes les méthodes disponibles sur chacune des variables ci-dessus, veuillez consulter la Javadoc
Si la propriété beanshell.preprocessor.init est définie, elle est utilisée pour charger un fichier d'initialisation, qui peut être utilisé pour définir des méthodes, etc. à utiliser dans le script BeanShell.
Préprocesseur JSR223 ¶
Le préprocesseur JSR223 permet d'appliquer le code de script JSR223 avant de prélever un échantillon.
Paramètres ¶
- Paramètres - chaîne contenant les paramètres comme une seule variable
- args - Tableau de chaînes contenant des paramètres, divisés en espaces blancs
Les variables JSR223 suivantes sont configurées pour être utilisées par le script :
- log - ( Logger ) - peut être utilisé pour écrire dans le fichier journal
- Étiquette - l'étiquette de chaîne
- FileName - le nom du fichier de script (le cas échéant)
- Paramètres - les paramètres (sous forme de chaîne)
- args - les paramètres sous la forme d'un tableau String (divisé en espaces)
- ctx - ( JMeterContext ) - donne accès au contexte
-
vars - ( JMeterVariables ) - donne un accès en lecture/écriture aux variables :
vars.get(clé); vars.put(clé,val); vars.putObject("OBJ1",nouvel objet()); vars.getObject("OBJ2"); - props - (JMeterProperties - classe java.util.Properties) - par exemple props.get("START.HMS"); props.put("PROP1","1234");
- sampler - ( Sampler )- donne accès au sampler courant
- OUT - System.out - par exemple OUT.println("message")
Pour plus de détails sur toutes les méthodes disponibles sur chacune des variables ci-dessus, veuillez consulter la Javadoc
Préprocesseur JDBC ¶
Le préprocesseur JDBC vous permet d'exécuter une instruction SQL juste avant l'exécution d'un échantillon. Cela peut être utile si votre exemple JDBC nécessite que certaines données soient dans la base de données et que vous ne pouvez pas les calculer dans un groupe de threads de configuration. Pour plus de détails, voir Requête JDBC .
Voir le plan de test suivant :
Dans le plan de test lié, " Créer un seuil de prix " JDBC PreProcessor appelle une procédure stockée pour créer un seuil de prix dans la base de données, celui-ci sera utilisé par " Calculer le seuil de prix ".

Paramètres utilisateur RegEx ¶
Permet de spécifier des valeurs dynamiques pour les paramètres HTTP extraits d'une autre requête HTTP à l'aide d'expressions régulières. Les paramètres utilisateur RegEx sont spécifiques aux threads individuels.
Ce composant vous permet de spécifier le nom de référence d'une expression régulière qui extrait les noms et les valeurs des paramètres de requête HTTP. Les numéros de groupe d'expressions régulières doivent être spécifiés pour le nom du paramètre et également pour la valeur du paramètre. Le remplacement ne se produira que pour les paramètres de l'échantillonneur qui utilise ces paramètres utilisateur RegEx dont le nom correspond

Paramètres ¶
Supposons que nous ayons une requête qui renvoie un formulaire avec 3 paramètres d'entrée et que nous voulions extraire la valeur de 2 d'entre eux pour les injecter dans la prochaine requête
- Créer une expression régulière de post-processeur pour la première requête HTTP
- refName - définit le nom d'une expression régulière Expression ( listParams )
-
expression régulière - expression qui extraira les noms d'entrée et les attributs de valeurs d'entrée
Ex : input name="([^"]+?)" value="([^"]+?)" - modèle - serait vide
- match nr - -1 (afin de parcourir toutes les correspondances possibles)
- Créer des paramètres utilisateur RegEx de préprocesseur pour la deuxième requête HTTP
- refName - définit le même nom de référence d'une expression régulière, serait listParams dans notre exemple
- nombre de groupes de noms de paramètres - nombre de groupes d'expressions régulières pour les noms de paramètres, serait 1 dans notre exemple
- nombre de groupes de valeurs de paramètres - nombre de groupes d'expressions régulières pour les valeurs de paramètres, serait 2 dans notre exemple
Voir aussi l' élément Regular Expression Extractor , qui est utilisé pour extraire les noms et les valeurs des paramètres
Délai d'expiration de l' échantillon ¶
Ce préprocesseur planifie une tâche de minuterie pour interrompre un échantillon s'il prend trop de temps à se terminer. Le délai d'attente est ignoré s'il est nul ou négatif. Pour que cela fonctionne, l'échantillonneur doit implémenter Interruptible. Les échantillonneurs suivants sont connus pour le faire :
AJP, BeanShell, FTP, HTTP, Soap, AccessLog, MailReader, JMS Subscriber, TCPSampler, TestAction, JavaSampler
L'élément de test est destiné à être utilisé lorsque les délais d'attente individuels tels que le délai de connexion ou le délai de réponse sont insuffisants, ou lorsque l'échantillonneur ne prend pas en charge les délais d'attente. Le délai d'attente doit être défini suffisamment long pour qu'il ne soit pas déclenché dans les tests normaux, mais suffisamment court pour interrompre les échantillons bloqués.
[Par défaut, JMeter utilise un Callable pour interrompre l'échantillonneur. Cela s'exécute dans le même thread que le temporisateur, donc si l'interruption prend beaucoup de temps, cela peut retarder le traitement des délais d'attente suivants. Cela ne devrait pas poser de problème, mais si nécessaire, la propriété InterruptTimer.useRunnable peut être définie sur true pour utiliser un thread Runnable séparé au lieu de Callable.]

Paramètres ¶
18.8 Post-processeurs ¶
Comme leur nom l'indique, les post-processeurs sont appliqués après les échantillonneurs. Notez qu'ils sont appliqués à tous les échantillonneurs dans la même portée, donc pour vous assurer qu'un post-processeur est appliqué uniquement à un échantillonneur particulier, ajoutez-le en tant qu'enfant de l'échantillonneur.
Les post-processeurs sont exécutés avant les assertions, de sorte qu'ils n'ont accès à aucun résultat d'assertion, et le statut de l'échantillon ne reflètera pas non plus les résultats des assertions. Si vous avez besoin d'accéder aux résultats d'assertion, essayez plutôt d'utiliser un écouteur. Notez également que la variable JMeterThread.last_sample_ok est définie sur « true » ou « false » après que toutes les assertions ont été exécutées.
Extracteur d'expression régulière ¶
Permet à l'utilisateur d'extraire des valeurs d'une réponse du serveur à l'aide d'une expression régulière de type Perl. En tant que post-processeur, cet élément s'exécutera après chaque requête Sample dans sa portée, en appliquant l'expression régulière, en extrayant les valeurs demandées, en générant la chaîne de modèle et en stockant le résultat dans le nom de variable donné.

Paramètres ¶
- Échantillon principal uniquement - ne s'applique qu'à l'échantillon principal
- Sous-échantillons uniquement - s'applique uniquement aux sous-échantillons
- Échantillon principal et sous-échantillons - s'applique aux deux.
- Nom de la variable JMeter à utiliser - l'extraction doit être appliquée au contenu de la variable nommée
- Corps - le corps de la réponse, par exemple le contenu d'une page Web (à l'exclusion des en-têtes)
-
Corps (non échappé) - le corps de la réponse, avec tous les codes d'échappement HTML remplacés. Notez que les échappements HTML sont traités sans tenir compte du contexte, de sorte que certaines substitutions incorrectes peuvent être effectuées.
Notez que cette option impacte fortement les performances, donc ne l'utilisez qu'en cas d'absolue nécessité et soyez conscient de ses impacts
-
Corps en tant que document - le texte d'extraction de divers types de documents via Apache Tika (voir la section Afficher l'arborescence des résultats du document).
Notez que l'option Corps en tant que document peut avoir un impact sur les performances, alors assurez-vous qu'elle est correcte pour votre test
- En-têtes de demande - peuvent ne pas être présents pour les exemples non HTTP
- En-têtes de réponse - peuvent ne pas être présents pour les échantillons non HTTP
- URL
- Code de réponse - par exemple 200
- Message de réponse - par exemple OK
- Utilisez une valeur de zéro pour indiquer que JMeter doit choisir une correspondance au hasard.
- Un nombre positif N signifie qu'il faut sélectionner la n ième correspondance.
- Les nombres négatifs sont utilisés conjointement avec le contrôleur ForEach - voir ci-dessous.
Cependant, si vous avez plusieurs éléments de test qui définissent la même variable, vous pouvez laisser la variable inchangée si l'expression ne correspond pas. Dans ce cas, supprimez la valeur par défaut une fois le débogage terminé.
Si le numéro de correspondance est défini sur un nombre non négatif et qu'une correspondance se produit, les variables sont définies comme suit :
- refName - la valeur du modèle
- refName_g n , où n = 0 , 1 , 2 - les groupes pour le match
- refName_g - le nombre de groupes dans la Regex (hors 0 )
Si aucune correspondance ne se produit, la variable refName est définie sur la valeur par défaut (sauf si celle-ci est absente). De plus, les variables suivantes sont supprimées :
- refName_g0
- refName_g1
- refName_g
Si le numéro de correspondance est défini sur un nombre négatif, toutes les correspondances possibles dans les données de l'échantillonneur sont traitées. Les variables sont définies comme suit :
- refName_matchNr - le nombre de correspondances trouvées ; pourrait être 0
- refName_ n , où n = 1 , 2 , 3 etc. - les chaînes générées par le modèle
- refName_ n _g m , où m = 0 , 1 , 2 - les groupes pour match n
- refName - toujours défini sur la valeur par défaut
- refName_g n - non défini
Notez que la variable refName est toujours définie sur la valeur par défaut dans ce cas et que les variables de groupe associées ne sont pas définies.
Voir également Assertion de réponse pour des exemples de spécification de modificateurs et pour plus d'informations sur les expressions régulières JMeter.
Extracteur de sélecteur CSS (auparavant : Extracteur CSS/JQuery ) ¶
Permet à l'utilisateur d'extraire des valeurs d'une réponse HTML de serveur à l'aide d'une syntaxe CSS Selector. En tant que post-processeur, cet élément s'exécutera après chaque requête Sample dans sa portée, en appliquant l'expression CSS/JQuery, en extrayant les nœuds demandés, en extrayant le nœud sous forme de texte ou de valeur d'attribut et stockera le résultat dans le nom de variable donné.

Paramètres ¶
- Échantillon principal uniquement - ne s'applique qu'à l'échantillon principal
- Sous-échantillons uniquement - s'applique uniquement aux sous-échantillons
- Échantillon principal et sous-échantillons - s'applique aux deux.
- Nom de la variable JMeter à utiliser - l'extraction doit être appliquée au contenu de la variable nommée
- E[foo] - un élément E avec un attribut " foo "
- ancêtre enfant - éléments enfants qui descendent de l'ancêtre, par exemple .body p trouve p éléments n'importe où sous un bloc avec la classe " body "
- :lt(n) - trouve les éléments dont l'index frère (c'est-à-dire sa position dans l'arbre DOM par rapport à son parent) est inférieur à n ; par exemple td:lt(3)
- :contains(text) - trouve les éléments qui contiennent le texte donné . La recherche est insensible à la casse ; par exemple p:contains(jsoup)
- …
Il s'agit de la fonction Element#attr(name) équivalente pour JSoup si un attribut est défini.
Si vide, c'est l'équivalent de la fonction Element#text() pour JSoup si aucune valeur n'est définie pour l'attribut.

- Utilisez une valeur de zéro pour indiquer que JMeter doit choisir une correspondance au hasard.
- Un nombre positif N signifie qu'il faut sélectionner la n ième correspondance.
- Les nombres négatifs sont utilisés conjointement avec le contrôleur ForEach - voir ci-dessous.
Cependant, si vous avez plusieurs éléments de test qui définissent la même variable, vous pouvez laisser la variable inchangée si l'expression ne correspond pas. Dans ce cas, supprimez la valeur par défaut une fois le débogage terminé.
Si le numéro de correspondance est défini sur un nombre non négatif et qu'une correspondance se produit, les variables sont définies comme suit :
- refName - la valeur du modèle
Si aucune correspondance ne se produit, la variable refName est définie sur la valeur par défaut (sauf si celle-ci est absente).
Si le numéro de correspondance est défini sur un nombre négatif, toutes les correspondances possibles dans les données de l'échantillonneur sont traitées. Les variables sont définies comme suit :
- refName_matchNr - le nombre de correspondances trouvées ; pourrait être 0
- refName_n , où n = 1 , 2 , 3 , etc. - les chaînes générées par le modèle
- refName - toujours défini sur la valeur par défaut
Notez que la variable refName est toujours définie sur la valeur par défaut dans ce cas.
Extracteur XPath2 ¶

Paramètres ¶
- Échantillon principal uniquement - ne s'applique qu'à l'échantillon principal
- Sous-échantillons uniquement - s'applique uniquement aux sous-échantillons
- Échantillon principal et sous-échantillons - s'applique aux deux.
- Nom de la variable JMeter à utiliser - l'extraction doit être appliquée au contenu de la variable nommée
Par exemple //title renverrait " <title>Apache JMeter</title> " plutôt que " Apache JMeter ".
Dans ce cas, //title/text() renverrait " Apache JMeter ".
- 0 : signifie aléatoire (valeur par défaut)
- -1 signifie extraire tous les résultats, ils seront nommés <nom de la variable> _N (où N va de 1 au nombre de résultats)
- X : signifie extraire le X ème résultat. Si ce X ème est supérieur au nombre de correspondances, alors rien n'est retourné. La valeur par défaut sera utilisée
Pour permettre une utilisation dans un contrôleur ForEach , cela fonctionne exactement de la même manière que l'extracteur XPath ci-dessus.
XPath2 Extractor fournit des outils intéressants tels qu'une syntaxe améliorée et bien plus de fonctions que dans sa première version.
Voici quelques exemples :
- abs(/livre/page[2])
- extrait la 2ème valeur absolue de la page d'un livre
- avg(/bibliothèque/livre/page)
- extrait le nombre moyen de pages de tous les livres des bibliothèques
- comparer(/livre[1]/page[2],/livre[2]/page[2])
- renvoie une valeur entière égale à 0 à si la 2 ème page du premier livre est égale à la 2 ème page du 2 ème livre, sinon renvoie -1.
Pour voir plus d'informations sur ces fonctions, veuillez vérifier les fonctions xPath2
Extracteur XPath ¶

Paramètres ¶
- Échantillon principal uniquement - ne s'applique qu'à l'échantillon principal
- Sous-échantillons uniquement - s'applique uniquement aux sous-échantillons
- Échantillon principal et sous-échantillons - s'applique aux deux.
- Nom de la variable JMeter à utiliser - l'extraction doit être appliquée au contenu de la variable nommée
- " Utiliser Tidy " doit être coché pour la réponse HTML. Cette réponse est convertie en XHTML valide (HTML compatible XML) à l'aide de Tidy
- " Utiliser Tidy " doit être décoché pour les réponses XHTML ou XML (par exemple RSS)
Par exemple //title renverrait " <title>Apache JMeter</title> " plutôt que " Apache JMeter ".
Dans ce cas, //title/text() renverrait " Apache JMeter ".
- 0 : signifie aléatoire
- -1 signifie extraire tous les résultats (valeur par défaut), ils seront nommés comme <nom de la variable> _N (où N va de 1 au nombre de résultats)
- X : signifie extraire le X ème résultat. Si ce X ème est supérieur au nombre de correspondances, alors rien n'est retourné. La valeur par défaut sera utilisée
Pour permettre une utilisation dans un ForEach Controller , les variables suivantes sont définies au retour :
- refName - défini sur la première (ou la seule) correspondance ; si aucune correspondance, alors défini par défaut
- refName_matchNr - défini sur le nombre de correspondances (peut être 0 )
- refName_n - n = 1 , 2 , 3 , etc. Réglé sur la 1 ère , 2 ème 3 ème correspondance etc.
XPath est un langage de requête ciblé principalement pour les transformations XSLT. Cependant, il est également utile comme langage de requête générique pour les données structurées. Voir Référence XPath ou Spécification XPath pour plus d'informations. Voici quelques exemples :
- /html/tête/titre
- extrait l'élément de titre de la réponse HTML
- /livre/page[2]
- extrait la 2ème page d'un livre
- /livre/page
- extrait toutes les pages d'un livre
- //form[@name='countryForm']//select[@name='country']/option[text()='République tchèque'])/@value
- extrait l'attribut de valeur de l'élément d'option qui correspond au texte ' République tchèque ' à l'intérieur de l'élément de sélection avec l'attribut de nom ' country ' à l'intérieur du formulaire avec l'attribut de nom ' countryForm '
- Tous les noms d'éléments et d'attributs sont convertis en minuscules
- Tidy tente de corriger les éléments mal imbriqués. Par exemple - l' ul/font/li d'origine (incorrect) devient l' ul/li/font correct
Pour contourner les limitations d'espace de noms de l'analyseur Xalan XPath (implémentation sur laquelle JMeter est basé), vous devez :
- fournissez un fichier de propriétés (si par exemple votre fichier s'appelle namespaces.properties ) qui contient des mappages pour les préfixes d'espace de noms :
prefix1=http\://foo.apache.org prefix2=http\://toto.apache.org …
- référencez ce fichier dans le fichier user.properties en utilisant la propriété :
xpath.namespace.config=espaces de noms.properties
//mon espace de noms : nom de la balise
//*[local-name()='tagname' and namespace-uri()='uri-for-namespace']uri-for-namespace mynamespace
Extracteur JSON JMESPath ¶

Paramètres ¶
- Échantillon principal uniquement - ne s'applique qu'à l'échantillon principal
- Sous-échantillons uniquement - s'applique uniquement aux sous-échantillons
- Échantillon principal et sous-échantillons - s'applique aux deux.
- Nom de la variable JMeter à utiliser - l'extraction doit être appliquée au contenu de la variable nommée
- 0 : signifie aléatoire
- -1 signifie extraire tous les résultats (valeur par défaut), ils seront nommés comme <nom de la variable> _N (où N va de 1 au nombre de résultats)
- X : signifie extraire le X ème résultat. Si ce X ème est supérieur au nombre de correspondances, alors rien n'est retourné. La valeur par défaut sera utilisée
JMESPath est un langage de requête pour JSON. Il est décrit dans une grammaire ABNF avec une spécification complète. Cela garantit que la syntaxe du langage est définie avec précision. Voir Référence JMESPath pour plus d'informations. Voici également quelques exemples Exemple JMESPath .
Gestionnaire d'action d'état de résultat ¶

Paramètres ¶
- Continuer - ignorer l'erreur et poursuivre le test
- Démarrer la boucle de thread suivante - n'exécute pas les échantillonneurs suivant l'échantillonneur en erreur pour l'itération en cours et redémarre la boucle à la prochaine itération
- Arrêter le thread - le thread actuel se termine
- Arrêter le test - l'ensemble du test est arrêté à la fin de tous les échantillons en cours.
- Arrêter le test maintenant - l'ensemble du test est arrêté brusquement. Tous les échantillonneurs en cours sont interrompus si possible.
Post-processeur BeanShell ¶
Le préprocesseur BeanShell permet d'appliquer du code arbitraire après avoir prélevé un échantillon.
Le post-processeur BeanShell n'ignore plus les échantillons avec des données de résultat de longueur nulle
Pour plus de détails sur l'utilisation de BeanShell, veuillez consulter le site Web de BeanShell.
L'élément de test prend en charge les méthodes ThreadListener et TestListener . Ceux-ci doivent être définis dans le fichier d'initialisation. Voir le fichier BeanShellListeners.bshrc pour des exemples de définitions.

Paramètres ¶
- Paramètres - chaîne contenant les paramètres comme une seule variable
- bsh.args - Tableau de chaînes contenant des paramètres, divisés en espaces blancs
Les variables BeanShell suivantes sont configurées pour être utilisées par le script :
- log - ( Logger ) - peut être utilisé pour écrire dans le fichier journal
- ctx - ( JMeterContext ) - donne accès au contexte
-
vars - ( JMeterVariables ) - donne un accès en lecture/écriture aux variables :
vars.get(clé); vars.put(clé,val); vars.putObject("OBJ1",nouvel objet()); - props - (JMeterProperties - classe java.util.Properties) - par exemple props.get("START.HMS"); props.put("PROP1","1234");
- prev - ( SampleResult ) - donne accès au précédent SampleResult
- data - (byte [])- donne accès aux données d'échantillon actuelles
Pour plus de détails sur toutes les méthodes disponibles sur chacune des variables ci-dessus, veuillez consulter la Javadoc
Si la propriété beanshell.postprocessor.init est définie, elle est utilisée pour charger un fichier d'initialisation, qui peut être utilisé pour définir des méthodes, etc. à utiliser dans le script BeanShell.
Post-processeur JSR223 ¶
Le post-processeur JSR223 permet d'appliquer le code de script JSR223 après avoir prélevé un échantillon.
Paramètres ¶
- Paramètres - chaîne contenant les paramètres comme une seule variable
- args - Tableau de chaînes contenant des paramètres, divisés en espaces blancs
Avant d'invoquer le script, certaines variables sont configurées. Notez qu'il s'agit de variables JSR223 - c'est-à-dire qu'elles peuvent être utilisées directement dans le script.
- log - ( Logger ) - peut être utilisé pour écrire dans le fichier journal
- Étiquette - l'étiquette de chaîne
- FileName - le nom du fichier de script (le cas échéant)
- Paramètres - les paramètres (sous forme de chaîne)
- args - les paramètres sous la forme d'un tableau String (divisé en espaces)
- ctx - ( JMeterContext ) - donne accès au contexte
-
vars - ( JMeterVariables ) - donne un accès en lecture/écriture aux variables :
vars.get(clé); vars.put(clé,val); vars.putObject("OBJ1",nouvel objet()); vars.getObject("OBJ2"); - props - (JMeterProperties - classe java.util.Properties) - par exemple props.get("START.HMS"); props.put("PROP1","1234");
- prev - ( SampleResult ) - donne accès au précédent SampleResult (le cas échéant)
- sampler - ( Sampler )- donne accès au sampler courant
- OUT - System.out - par exemple OUT.println("message")
Pour plus de détails sur toutes les méthodes disponibles sur chacune des variables ci-dessus, veuillez consulter la Javadoc
Post-processeur JDBC ¶
Le post-processeur JDBC vous permet d'exécuter une instruction SQL juste après l'exécution d'un échantillon. Cela peut être utile si votre exemple JDBC modifie certaines données et que vous souhaitez réinitialiser l'état à ce qu'il était avant l'exécution de l'exemple JDBC.
Dans le plan de test lié, " JDBC PostProcessor " JDBC PostProcessor appelle une procédure stockée pour supprimer de la base de données le prix limite qui a été créé par PreProcessor.

Extracteur JSON ¶
Le post-processeur JSON vous permet d'extraire des données des réponses JSON à l'aide de la syntaxe JSON-PATH. Ce post-processeur est très similaire à l'extracteur d'expressions régulières. Il doit être placé en tant qu'enfant de HTTP Sampler ou de tout autre échantillonneur qui a des réponses. Il vous permettra d'extraire très facilement du contenu textuel, voir Syntaxe JSON Path .
Paramètres ¶
- 0 : signifie aléatoire (valeur par défaut)
- -1 signifie extraire tous les résultats, ils seront nommés <nom de la variable> _N (où N va de 1 au nombre de résultats)
- X : signifie extraire le X ème résultat. Si ce X ème est supérieur au nombre de correspondances, alors rien n'est retourné. La valeur par défaut sera utilisée

Extracteur de bordure ¶
Permet à l'utilisateur d'extraire des valeurs d'une réponse de serveur en utilisant les limites gauche et droite. En tant que post-processeur, cet élément s'exécutera après chaque requête Sample dans sa portée, testant les limites, extrayant les valeurs demandées, générant la chaîne de modèle et stockant le résultat dans le nom de variable donné.

Paramètres ¶
- Échantillon principal uniquement - ne s'applique qu'à l'échantillon principal
- Sous-échantillons uniquement - s'applique uniquement aux sous-échantillons
- Échantillon principal et sous-échantillons - s'applique aux deux.
- Nom de la variable JMeter à utiliser - l'assertion doit être appliquée au contenu de la variable nommée
- Corps - le corps de la réponse, par exemple le contenu d'une page Web (à l'exclusion des en-têtes)
-
Corps (non échappé) - le corps de la réponse, avec tous les codes d'échappement HTML remplacés. Notez que les échappements HTML sont traités sans tenir compte du contexte, de sorte que certaines substitutions incorrectes peuvent être effectuées.
Notez que cette option impacte fortement les performances, donc ne l'utilisez qu'en cas d'absolue nécessité et soyez conscient de ses impacts
-
Corps en tant que document - le texte d'extraction de divers types de documents via Apache Tika (voir la section Afficher l'arborescence des résultats du document).
Notez que l'option Corps en tant que document peut avoir un impact sur les performances, alors assurez-vous qu'elle est correcte pour votre test
- En-têtes de demande - peuvent ne pas être présents pour les exemples non HTTP
- En-têtes de réponse - peuvent ne pas être présents pour les échantillons non HTTP
- URL
- Code de réponse - par exemple 200
- Message de réponse - par exemple OK
- Utilisez une valeur de zéro pour indiquer que JMeter doit choisir une correspondance au hasard.
- Un nombre positif N signifie qu'il faut sélectionner la n ième correspondance.
- Les nombres négatifs sont utilisés conjointement avec le contrôleur ForEach - voir ci-dessous.
Cependant, si vous avez plusieurs éléments de test qui définissent la même variable, vous pouvez laisser la variable inchangée si l'expression ne correspond pas. Dans ce cas, supprimez la valeur par défaut une fois le débogage terminé.
Si le numéro de correspondance est défini sur un nombre non négatif et qu'une correspondance se produit, les variables sont définies comme suit :
- refName - la valeur de l'extraction
Si aucune correspondance ne se produit, la variable refName est définie sur la valeur par défaut (sauf si celle-ci est absente).
Si le numéro de correspondance est défini sur un nombre négatif, toutes les correspondances possibles dans les données de l'échantillonneur sont traitées. Les variables sont définies comme suit :
- refName_matchNr - le nombre de correspondances trouvées ; pourrait être 0
- refName_ n , où n = 1 , 2 , 3 etc. - les chaînes générées par le modèle
- refName_ n _g m , où m = 0 , 1 , 2 - les groupes pour match n
- refName - toujours défini sur la valeur par défaut
Notez que la variable refName est toujours définie sur la valeur par défaut dans ce cas et que les variables de groupe associées ne sont pas définies.
18.9 Fonctionnalités diverses ¶
Plan de test ¶
Le plan de test est l'endroit où les paramètres généraux d'un test sont spécifiés.
Des variables statiques peuvent être définies pour des valeurs répétées tout au long d'un test, telles que des noms de serveur. Par exemple, la variable SERVER pourrait être définie comme www.example.com , et le reste du plan de test pourrait s'y référer comme ${SERVER} . Cela simplifie le changement de nom ultérieur.
Si le même nom de variable est réutilisé sur un ou plusieurs éléments de configuration des variables définies par l'utilisateur , la valeur est définie sur la dernière définition du plan de test (lecture de haut en bas). Ces variables doivent être utilisées pour les éléments qui peuvent changer entre les exécutions de test, mais qui restent les mêmes pendant une exécution de test.
La sélection de Tests fonctionnels indique à JMeter d'enregistrer les informations d'échantillon supplémentaires - Données de réponse et Données d'échantillonneur - dans tous les fichiers de résultats. Cela augmente les ressources nécessaires pour exécuter un test et peut avoir un impact négatif sur les performances de JMeter. Si davantage de données sont requises pour un échantillonneur particulier uniquement, ajoutez-y un écouteur et configurez les champs selon vos besoins.
De plus, une option existe ici pour demander à JMeter d'exécuter le groupe de threads en série plutôt qu'en parallèle.
Exécuter les groupes de threads tearDown après l'arrêt des threads principaux : si cette option est sélectionnée, les groupes de démontage (le cas échéant) seront exécutés après l'arrêt progressif des threads principaux. Les threads tearDown ne seront pas exécutés si le test est arrêté de force.
Le plan de test fournit désormais un moyen simple d'ajouter un paramètre de chemin de classe à un plan de test spécifique. La fonctionnalité est additive, ce qui signifie que vous pouvez ajouter des fichiers jar ou des répertoires, mais la suppression d'une entrée nécessite le redémarrage de JMeter.
Les propriétés JMeter fournissent également une entrée pour charger des chemins de classe supplémentaires. Dans jmeter.properties , modifiez " user.classpath " ou " plugin_dependency_paths " pour inclure des bibliothèques supplémentaires. Voir Classpath de JMeter et Configuration de JMeter pour plus de détails.

Groupe de threads ¶
Un groupe de threads définit un groupe d'utilisateurs qui exécuteront un cas de test particulier sur votre serveur. Dans l'interface graphique du groupe de threads, vous pouvez contrôler le nombre d'utilisateurs simulés (nombre de threads), le temps de montée en puissance (combien de temps il faut pour démarrer tous les threads), le nombre de fois pour effectuer le test et, éventuellement, un début et l'heure d'arrêt du test.
Voir aussi groupe de threads tearDown et groupe de threads setUp .
Lors de l'utilisation du planificateur, JMeter exécute le groupe de threads jusqu'à ce que le nombre de boucles soit atteint ou que la durée/l'heure de fin soit atteinte - selon la première éventualité. Notez que la condition n'est vérifiée qu'entre les échantillons ; lorsque la condition de fin est atteinte, ce thread s'arrête. JMeter n'interrompt pas les échantillonneurs qui attendent une réponse, de sorte que l'heure de fin peut être retardée arbitrairement.

Depuis JMeter 3.0, vous pouvez exécuter une sélection de groupes de threads en les sélectionnant et en cliquant avec le bouton droit de la souris. Un menu contextuel apparaîtra :

Notez que vous avez trois options pour exécuter la sélection des groupes de threads :
- Commencer
- Démarrer les groupes de threads sélectionnés uniquement
- Commencez sans pause
- Démarrer les groupes de threads sélectionnés uniquement mais sans exécuter les minuteries
- Valider
- Démarrez les groupes de threads sélectionnés uniquement en utilisant le mode de validation. Par défaut, cela exécute le groupe de threads en mode validation (voir ci-dessous)
ce mode permet une validation rapide d'un groupe de threads en l'exécutant avec un thread, une itération, sans minuterie et sans délai de démarrage défini sur 0 . Le comportement peut être modifié avec certaines propriétés en définissant dans user.properties :
- testplan_validation.nb_threads_per_thread_group
- Nombre de threads à utiliser pour valider un groupe de threads, par défaut 1
- testplan_validation.ignore_timers
- Ignorer les temporisateurs lors de la validation du groupe de threads du plan, par défaut 1
- testplan_validation.number_iterations
- Nombre d'itérations à utiliser pour valider un groupe de threads
- testplan_validation.tpc_force_100_pct
- Indique s'il faut forcer le contrôleur de débit en mode pourcentage à s'exécuter comme si le pourcentage était de 100 %. La valeur par défaut est false
Paramètres ¶
- Continuer - ignorer l'erreur et poursuivre le test
- Démarrer la boucle de thread suivante - ignorez l'erreur, démarrez la boucle suivante et continuez le test
- Arrêter le thread - le thread actuel se termine
- Arrêter le test - l'ensemble du test est arrêté à la fin de tous les échantillons en cours.
- Arrêter le test maintenant - l'ensemble du test est arrêté brusquement. Tous les échantillonneurs en cours sont interrompus si possible.
S'il n'est pas sélectionné, tous les threads sont créés au démarrage du test (ils s'arrêtent ensuite pendant la proportion appropriée du temps de montée en puissance). Il s'agit de la valeur par défaut d'origine et convient aux tests où les threads sont actifs pendant la majeure partie du test.
Gestionnaire SSL ¶
Le gestionnaire SSL est un moyen de sélectionner un certificat client afin que vous puissiez tester les applications qui utilisent l'infrastructure à clé publique (PKI). Il n'est nécessaire que si vous n'avez pas configuré les propriétés système appropriées.
Vous pouvez soit utiliser un magasin de clés au format Java Key Store (JKS), soit un fichier Public Key Certificate Standard #12 (PKCS12) pour vos certificats clients. Il existe une fonctionnalité des bibliothèques JSSE qui nécessite que vous ayez au moins un mot de passe à six caractères sur votre clé (au moins pour l'utilitaire keytool fourni avec votre JDK).
Pour sélectionner le certificat client, choisissez dans la barre de menus. Il vous sera présenté un outil de recherche de fichiers qui recherche les fichiers PKCS12 par défaut. Votre fichier PKCS12 doit avoir l'extension ' .p12 ' pour que SSL Manager le reconnaisse comme un fichier PKCS12. Tout autre fichier sera traité comme un magasin de clés JKS moyen. Si JSSE est correctement installé, le mot de passe vous sera demandé. La zone de texte ne masque pas les caractères que vous tapez à ce stade. Assurez-vous donc que personne ne regarde par-dessus votre épaule. L'implémentation actuelle suppose que le mot de passe du magasin de clés est également le mot de passe de la clé privée du client avec lequel vous souhaitez vous authentifier.
Ou vous pouvez définir les propriétés système appropriées - voir le fichier system.properties .
La prochaine fois que vous exécuterez votre test, le gestionnaire SSL examinera votre magasin de clés pour voir s'il dispose d'au moins une clé. S'il n'y a qu'une seule clé, SSL Manager la sélectionnera pour vous. S'il y a plus d'une clé, il sélectionne actuellement la première clé. Il n'existe actuellement aucun moyen de sélectionner d'autres entrées dans le magasin de clés, la clé souhaitée doit donc être la première.
Choses à surveillerVotre certificat d'autorité de certification (CA) doit être correctement installé s'il n'est pas signé par l'un des cinq certificats CA livrés avec votre JDK. Une méthode pour l'installer consiste à importer votre certificat CA dans un fichier JKS et à nommer le fichier JKS " jssecacerts ". Placez le fichier dans le dossier lib/security de votre JRE . Ce fichier sera lu avant le fichier " cacerts " dans le même répertoire. Gardez à l'esprit que tant que le fichier " jssecacerts " existe, les certificats installés dans " cacerts " ne seront pas utilisés. Cela peut vous causer des problèmes. Si cela ne vous dérange pas d'importer votre certificat CA dans le fichier " cacerts", vous pouvez alors vous authentifier auprès de tous les certificats CA installés.
Enregistreur de script de test HTTP(S) (auparavant : Serveur proxy HTTP ) ¶
L'enregistreur de script de test HTTP(S) permet à JMeter d'intercepter et d'enregistrer vos actions pendant que vous naviguez dans votre application Web avec votre navigateur normal. JMeter créera des exemples d'objets de test et les stockera directement dans votre plan de test au fur et à mesure (afin que vous puissiez visualiser les échantillons de manière interactive pendant que vous les créez).
Assurez-vous de lire cette page wiki pour configurer correctement JMeter.
Pour utiliser l'enregistreur, ajoutez l'élément HTTP(S) Test Script Recorder. Faites un clic droit sur l'élément Plan de test pour obtenir le menu Ajouter : ( ).
L'enregistreur est implémenté en tant que serveur proxy HTTP(S). Vous devez configurer votre navigateur pour utiliser le proxy pour toutes les requêtes HTTP et HTTPS.
Utilisez idéalement le mode de navigation privée lors de l'enregistrement de la session. Cela devrait garantir que le navigateur démarre sans cookies stockés et empêcher l'enregistrement de certaines modifications. Par exemple, Firefox n'autorise pas l'enregistrement permanent des remplacements de certificat.
Enregistrement HTTPS et certificats
Les connexions HTTPS utilisent des certificats pour authentifier la connexion entre le navigateur et le serveur Web. Lors de la connexion via HTTPS, le serveur présente le certificat au navigateur. Pour authentifier le certificat, le navigateur vérifie que le certificat du serveur est signé par une autorité de certification (CA) liée à l'une de ses CA racines intégrées.
JMeter doit utiliser son propre certificat pour lui permettre d'intercepter la connexion HTTPS du navigateur. En effet, JMeter doit faire semblant d'être le serveur cible.
JMeter générera son ou ses propres certificats. Ceux-ci sont générés avec une période de validité définie par la propriété proxy.cert.validity , 7 jours par défaut et des mots de passe aléatoires. Si JMeter détecte qu'il s'exécute sous Java 8 ou version ultérieure, il générera des certificats pour chaque serveur cible si nécessaire (mode dynamique) à moins que la propriété suivante ne soit définie : proxy.cert.dynamic_keys=false. Lors de l'utilisation du mode dynamique, le certificat sera pour le nom d'hôte correct et sera signé par un certificat CA généré par JMeter. Par défaut, ce certificat CA ne sera pas approuvé par le navigateur, mais il peut être installé en tant que certificat approuvé. Une fois cela fait, les certificats de serveur générés seront acceptés par le navigateur. Cela présente l'avantage que même les ressources HTTPS intégrées peuvent être interceptées et qu'il n'est pas nécessaire de remplacer les vérifications du navigateur pour chaque nouveau serveur.
À moins qu'un magasin de clés ne soit fourni (et que vous définissiez la propriété proxy.cert.alias ), JMeter doit utiliser l'application keytool pour créer les entrées du magasin de clés. JMeter inclut du code pour vérifier que keytool est disponible en regardant à divers endroits standard. Si JMeter ne parvient pas à trouver l'application keytool, il signalera une erreur. Si nécessaire, la propriété système keytool.directory peut être utilisée pour indiquer à JMeter où trouver keytool. Cela doit être défini dans le fichier system.properties .
Les certificats JMeter sont générés (si nécessaire) lorsque le bouton Démarrer est enfoncé.
Si nécessaire, vous pouvez forcer JMeter à régénérer le keystore (et les certificats exportés - ApacheJMeterTemporaryRootCA[.usr|.crt] ) en supprimant le fichier keystore proxyserver.jks du répertoire JMeter.
Ce certificat ne fait pas partie des certificats auxquels les navigateurs font normalement confiance et ne sera pas destiné au bon hôte.
En conséquence:
- Le navigateur devrait afficher une boîte de dialogue vous demandant si vous souhaitez accepter le certificat ou non. Par exemple:
1) Le nom du serveur " www.example.com " ne correspond pas au nom du certificat " _ JMeter Root CA pour l'enregistrement (INSTALLER UNIQUEMENT SI C'EST LE VÔTRE) ". Quelqu'un essaie peut-être de vous espionner. 2) Le certificat pour " _ JMeter Root CA for recording (INSTALL ONLY IF IT S YOURS) " est signé par l'autorité de certification inconnue " _ JMeter Root CA pour l'enregistrement (INSTALLER UNIQUEMENT SI C'EST LE VÔTRE) ". Il n'est pas possible de vérifier qu'il s'agit d'un certificat valide.
Vous devrez accepter le certificat afin de permettre au proxy JMeter d'intercepter le trafic SSL afin de l'enregistrer. Cependant, n'acceptez pas ce certificat de façon permanente ; il ne devrait être accepté que temporairement. Les navigateurs n'invitent ce dialogue que pour le certificat de l'URL principale, pas pour les ressources chargées dans la page, telles que les images, les fichiers CSS ou JavaScript hébergés sur un CDN externe sécurisé. Si vous avez de telles ressources (gmail en a par exemple), vous devrez d'abord naviguer manuellement vers ces autres domaines afin d'accepter le certificat de JMeter pour eux. Vérifiez dans jmeter.log les domaines sécurisés pour lesquels vous devez enregistrer un certificat. - Si le navigateur a déjà enregistré un certificat validé pour ce domaine, le navigateur détectera JMeter comme une faille de sécurité et refusera de charger la page. Si tel est le cas, vous devez supprimer le certificat de confiance du magasin de clés de votre navigateur.
Les versions de JMeter à partir de la version 2.10 prennent toujours en charge cette méthode, et continueront à le faire si vous définissez la propriété suivante : proxy.cert.alias Les propriétés suivantes peuvent être utilisées pour modifier le certificat utilisé :
- proxy.cert.directory - le répertoire dans lequel trouver le certificat (par défaut = JMeter bin/ )
- proxy.cert.file - nom du fichier keystore (par défaut " proxyserver.jks ")
- proxy.cert.keystorepass - mot de passe du magasin de clés (mot de passe par défaut ) [Ignoré si vous utilisez un certificat JMeter]
- proxy.cert.keypassword - mot de passe de la clé de certificat (mot de passe par défaut ) [Ignoré si vous utilisez un certificat JMeter]
- proxy.cert.type - le type de certificat (par défaut " JKS ") [Ignoré si vous utilisez un certificat JMeter]
- proxy.cert.factory - l'usine (par défaut " SunX509 ") [Ignoré si vous utilisez un certificat JMeter]
- proxy.cert.alias - l'alias de la clé à utiliser. Si cela est défini, JMeter n'essaie pas de générer son ou ses propres certificats.
- proxy.ssl.protocol - le protocole à utiliser (par défaut " SSLv3 ")
Installation du certificat JMeter CA pour l'enregistrement HTTPS
Comme mentionné ci-dessus, lorsqu'il est exécuté sous Java 8, JMeter peut générer des certificats pour chaque serveur. Pour que cela fonctionne correctement, le certificat de signature de l'autorité de certification racine utilisé par JMeter doit être approuvé par le navigateur. La première fois que l'enregistreur est démarré, il générera les certificats si nécessaire. Le certificat de l'autorité de certification racine est exporté dans un fichier portant le nom ApacheJMeterTemporaryRootCA dans le répertoire de lancement actuel. Une fois les certificats configurés, JMeter affichera une boîte de dialogue avec les détails du certificat actuel. À ce stade, le certificat peut être importé dans le navigateur, conformément aux instructions ci-dessous.
Notez qu'une fois que le certificat de l'autorité de certification racine a été installé en tant qu'autorité de certification de confiance, le navigateur fera confiance à tous les certificats signés par celui-ci. Jusqu'à ce que le certificat expire ou que le certificat soit supprimé du navigateur, il n'avertit pas l'utilisateur que le certificat est utilisé. Ainsi, toute personne pouvant obtenir le magasin de clés et le mot de passe peut utiliser le certificat pour générer des certificats qui seront acceptés par tous les navigateurs qui font confiance au certificat de l'autorité de certification racine JMeter. Pour cette raison, le mot de passe pour le magasin de clés et les clés privées sont générés de manière aléatoire et une courte période de validité est utilisée. Les mots de passe sont stockés dans la zone des préférences locales. Assurez-vous que seuls les utilisateurs de confiance ont accès à l'hôte avec le magasin de clés.

Installation du certificat dans Firefox
Choisissez les options suivantes :
- Outils / Options
- Avancé / Certificats
- Afficher les certificats
- Les autorités
- Importer …
- Accédez au répertoire de lancement de JMeter et cliquez sur le fichier ApacheJMeterTemporaryRootCA.crt , appuyez sur Ouvrir
- Cliquez sur Afficher et vérifiez que les détails du certificat correspondent à ceux affichés par l'enregistreur de script de test JMeter
- Si OK, sélectionnez « Faire confiance à cette autorité de certification pour identifier les sites Web », et appuyez sur OK
- Fermez les boîtes de dialogue en appuyant sur OK si nécessaire
Installation du certificat dans Chrome ou Internet Explorer
Chrome et Internet Explorer utilisent le même magasin de confiance pour les certificats.
- Accédez au répertoire de lancement de JMeter et cliquez sur le fichier ApacheJMeterTemporaryRootCA.crt et ouvrez-le
- Cliquez sur l'onglet " Détails " et vérifiez que les détails du certificat correspondent à ceux affichés par l'enregistreur de script de test JMeter
- Si OK, retournez à l' onglet « Général », et cliquez sur « Installer le certificat… » et suivez les invites de l'assistant
Installation du certificat dans Opera
- Outils / Préférences / Avancé / Sécurité
- Gérer les certificats…
- Sélectionnez l' onglet « Intermédiaire », cliquez sur « Importer… »
- Accédez au répertoire de lancement de JMeter et cliquez sur le fichier ApacheJMeterTemporaryRootCA.usr et ouvrez-le.

Paramètres ¶
Par exemple, *.example.com,*.subdomain.example.com
Notez que les domaines génériques ne s'appliquent qu'à un seul niveau, c'est-à-dire que abc.subdomain.example.com correspond à *.subdomain.example.com mais pas à *.example.com
- Ne regroupez pas les échantillonneurs - stockez tous les échantillonneurs enregistrés de manière séquentielle, sans aucun regroupement.
- Ajouter des séparateurs entre les groupes - ajoutez un contrôleur nommé " -------------- " pour créer une séparation visuelle entre les groupes. Sinon, les échantillonneurs sont tous stockés séquentiellement.
- Placez chaque groupe dans un nouveau contrôleur - créez un nouveau contrôleur simple pour chaque groupe et stockez-y tous les échantillonneurs de ce groupe.
- Enregistrez uniquement le 1 er sampler de chaque groupe - seule la première demande de chaque groupe sera enregistrée. Les indicateurs " Suivre les redirections " et " Récupérer toutes les ressources intégrées… " seront activés dans ces échantillonneurs.
- Placez chaque groupe dans un nouveau contrôleur de transaction - créez un nouveau contrôleur de transaction pour chaque groupe et stockez-y tous les échantillonneurs de ce groupe.
Enregistrement et redirections
Pendant l'enregistrement, le navigateur suivra une réponse de redirection et générera une demande supplémentaire. Le proxy enregistrera à la fois la demande d'origine et la demande redirigée (sous réserve des exclusions configurées). Les exemples générés ont " Follow Redirects " sélectionné par défaut, car c'est généralement mieux.
Maintenant, si JMeter est configuré pour suivre la redirection pendant la relecture, il émettra la demande d'origine, puis rejouera la demande de redirection qui a été enregistrée. Pour éviter cette relecture en double, JMeter essaie de détecter quand un échantillon est le résultat d'une redirection précédente. Si la réponse actuelle est une redirection, JMeter enregistrera l'URL de redirection. Lorsque la requête suivante est reçue, elle est comparée à l'URL de redirection enregistrée et s'il y a une correspondance, JMeter désactivera l'échantillon généré. Il ajoute également des commentaires à la chaîne de redirection. Cela suppose que toutes les requêtes d'une chaîne de redirection se succéderont sans aucune requête intermédiaire. Pour désactiver la détection de redirection, définissez la propriété proxy.redirect.disabling=false
Inclut et exclut
Les modèles d'inclusion et d'exclusion sont traités comme des expressions régulières (à l'aide de Jakarta ORO). Ils seront mis en correspondance avec le nom d'hôte, le port (réel ou implicite), le chemin et la requête (le cas échéant) de chaque requête de navigateur. Si l'URL que vous parcourez est
" http://localhost/jmeter/index.html?username=xxxx ",
alors l'expression régulière sera testée par rapport à la chaîne :
" localhost:80/jmeter/index.html?username=xxxx ".
Ainsi, si vous souhaitez inclure tous les fichiers .html , votre expression régulière pourrait ressembler à :
" .*\.html(\?.*)? " - ou " .*\.html
si vous savez qu'il n'y a pas de chaîne de requête ou vous ne voulez que des pages html sans chaînes de requête.
S'il existe des modèles d'inclusion, l'URL doit correspondre à au moins l'un des modèles , sinon elle ne sera pas enregistrée. S'il existe des modèles d'exclusion, l'URL ne doit correspondre à aucun des modèles , sinon elle ne sera pas enregistrée. En utilisant une combinaison d'inclusions et d'exclusions, vous devriez pouvoir enregistrer ce qui vous intéresse et ignorer ce qui ne vous intéresse pas.
Ainsi " \.html " ne correspondra pas à localhost:80/index.html
Capture de données POST binaires
JMeter est capable de capturer des données POST binaires. Pour configurer quels types de contenu sont traités comme binaires, mettez à jour la propriété JMeter proxy.binary.types . Les paramètres par défaut sont les suivants :
# Ces types de contenu seront gérés en enregistrant la requête dans un fichier : proxy.binary.types=application/x-amf,application/x-java-serialized-object # Les fichiers seront enregistrés dans ce répertoire : proxy.binary.directory=utilisateur.dir # Les fichiers seront créés avec ce suffixe de fichier : proxy.binary.filesuffix=.binaire
Ajout de minuteries
Il est également possible que le proxy ajoute des temporisateurs au script enregistré. Pour ce faire, créez un minuteur directement dans le composant HTTP(S) Test Script Recorder. Le proxy placera une copie de cette minuterie dans chaque échantillon qu'il enregistre, ou dans le premier échantillon de chaque groupe si vous utilisez le regroupement. Cette copie sera ensuite analysée pour les occurrences de la variable ${T} dans ses propriétés, et toutes ces occurrences seront remplacées par l'intervalle de temps depuis l'échantillonneur précédent enregistré (en millisecondes).
Lorsque vous êtes prêt à commencer, appuyez sur " démarrer ".
Où les échantillons sont-ils enregistrés ?
JMeter place les échantillons enregistrés dans le contrôleur cible que vous choisissez. Si vous choisissez l'option par défaut " Utiliser le contrôleur d'enregistrement ", ils seront stockés dans le premier contrôleur d'enregistrement trouvé dans l'arborescence des objets de test (assurez-vous donc d'ajouter un contrôleur d'enregistrement avant de commencer l'enregistrement).
Si le proxy ne semble pas enregistrer d'échantillons, cela peut être dû au fait que le navigateur n'utilise pas réellement le proxy. Pour vérifier si c'est le cas, essayez d'arrêter le proxy. Si le navigateur télécharge toujours des pages, c'est qu'il n'envoyait pas de requêtes via le proxy. Vérifiez les options du navigateur. Si vous essayez d'enregistrer à partir d'un serveur fonctionnant sur le même hôte, vérifiez que le navigateur n'est pas défini sur « Contourner le serveur proxy pour les adresses locales » (cet exemple provient d'IE7, mais il y aura des options similaires pour d'autres navigateurs). Si JMeter n'enregistre pas les URL du navigateur telles que http://localhost/ ou http://127.0.0.1/ , essayez d'utiliser le nom d'hôte ou l'adresse IP sans bouclage, par exemple http://myhost/ ou http://192.168. 0,2/ .
Gestion des valeurs par défaut des requêtes HTTP
Si l'enregistreur de script de test HTTP(S) trouve des valeurs par défaut de requête HTTP activées directement dans le contrôleur où les échantillons sont stockés, ou directement dans l'un de ses contrôleurs parents, les échantillons enregistrés auront des champs vides pour les valeurs par défaut que vous avez spécifiées. Vous pouvez contrôler davantage ce comportement en plaçant un élément HTTP Request Defaults directement dans l'enregistreur de script de test HTTP(S), dont les valeurs non vides remplaceront celles des autres HTTP Request Defaults. Voir Meilleures pratiques avec l'enregistreur de script de test HTTP(S) pour plus d'informations.
Remplacement de variable définie par l'utilisateur
De même, si l'enregistreur de script de test HTTP(S) trouve des variables définies par l'utilisateur (UDV) directement dans le contrôleur où les échantillons sont stockés, ou directement dans l'un de ses contrôleurs parents, les échantillons enregistrés auront toutes les occurrences des valeurs de ces variables. remplacé par la variable correspondante. Encore une fois, vous pouvez placer des variables définies par l'utilisateur directement dans l'enregistreur de script de test HTTP(S) pour remplacer les valeurs à remplacer. Voir Meilleures pratiques avec l'enregistreur de script de test pour plus d'informations.
Remplacement par des Variables : par défaut, le serveur Proxy recherche toutes les occurrences des valeurs UDV. Si vous définissez la variable WEB avec la valeur www , par exemple, la chaîne www sera remplacée par ${WEB} partout où elle se trouve. Pour éviter que cela ne se produise partout, cochez la case " Regex Matching ". Cela indique au serveur proxy de traiter les valeurs comme des regex (en utilisant les comparateurs de regex compatibles perl5 fournis par ORO).
Si " Regex Matching " est sélectionné, chaque variable sera compilée dans une regex compatible perl incluse dans \b( et )\b . De cette façon, chaque correspondance commencera et se terminera à une limite de mots.
Si vous ne voulez pas que votre regex soit entourée de ces correspondances de limites, vous devez enfermer votre regex entre parenthèses, par exemple ('.*?') pour faire correspondre 'name' à You can call me 'name' .
Si vous voulez faire correspondre une chaîne entière uniquement, mettez-la entre (^ et $) , par exemple (^thus$) . Les parenthèses sont nécessaires, car les caractères de délimitation normalement ajoutés empêcheront ^ et $ de correspondre.
Si vous souhaitez faire correspondre /images au début d'une chaîne uniquement, utilisez la valeur (^/images) . Jakarta ORO prend également en charge l'anticipation de largeur nulle, de sorte que l'on peut faire correspondre /images/… mais conserver le / final dans la sortie en utilisant (^/images(?=/)) .
Faites attention aux correspondances qui se chevauchent. Par exemple, la valeur .* en tant que regex dans une variable nommée regex correspondra en partie à une variable remplacée précédente, ce qui entraînera quelque chose comme ${{regex} , ce qui n'est probablement pas le résultat souhaité.
S'il y a des problèmes d'interprétation des variables en tant que modèles, ceux-ci sont signalés dans jmeter.log , alors assurez-vous de vérifier cela si les UDV ne fonctionnent pas comme prévu.
Lorsque vous avez terminé d'enregistrer vos échantillons de test, arrêtez le serveur proxy (appuyez sur le bouton « stop »). N'oubliez pas de réinitialiser les paramètres de proxy de votre navigateur. Maintenant, vous pouvez trier et réorganiser le script de test, ajouter des minuteries, des écouteurs, un gestionnaire de cookies, etc.
Comment puis-je également enregistrer les réponses du serveur ?
Placez simplement un écouteur Afficher l'arborescence des résultats en tant qu'enfant de l'enregistreur de script de test HTTP(S) et les réponses seront affichées. Vous pouvez également ajouter un post-processeur de sauvegarde des réponses à un fichier qui enregistrera les réponses dans des fichiers.
Associer les requêtes aux réponses
Si vous définissez la propriété proxy.number.requests=true , JMeter ajoutera un numéro à chaque échantillonneur et à chaque réponse. Notez qu'il peut y avoir plus de réponses que d'échantillonneurs si des exclusions ou des inclusions ont été utilisées. Les réponses qui ont été exclues auront des étiquettes entre [ et ], par exemple [23 /favicon.ico]
Gestionnaire de cookies
Si le serveur que vous testez utilise des cookies, n'oubliez pas d'ajouter un gestionnaire de cookies HTTP au plan de test lorsque vous avez terminé de l'enregistrer. Pendant l'enregistrement, le navigateur gère tous les cookies, mais JMeter a besoin d'un gestionnaire de cookies pour gérer les cookies lors d'un test. Le serveur JMeter Proxy transmet tous les cookies envoyés par le navigateur lors de l'enregistrement, mais ne les enregistre pas dans le plan de test car ils sont susceptibles de changer entre les exécutions.
Gestionnaire d'autorisation
L'enregistreur de script de test HTTP(S) récupère l'en-tête " Authentication ", tente de calculer la stratégie d'authentification. Si le gestionnaire d'autorisations a été ajouté manuellement au contrôleur cible, HTTP(S) Test Script Recorder le trouvera et ajoutera l'autorisation (celles qui correspondent seront supprimées). Sinon, le gestionnaire d'autorisations sera ajouté au contrôleur cible avec l'objet d'autorisation. Vous devrez peut-être corriger les valeurs calculées automatiquement après l'enregistrement.
Télécharger des fichiers
Certains navigateurs (par exemple Firefox et Opera) n'incluent pas le nom complet d'un fichier lors du téléchargement de fichiers. Cela peut entraîner l'échec du serveur proxy JMeter. Une solution consiste à s'assurer que tous les fichiers à télécharger se trouvent dans le répertoire de travail de JMeter, soit en y copiant les fichiers, soit en démarrant JMeter dans le répertoire contenant les fichiers.
Enregistrement de protocoles non textuels basés sur HTTP non disponibles nativement dans JMeter
Vous devrez peut-être enregistrer un protocole HTTP qui n'est pas géré par défaut par JMeter (Custom Binary Protocol, Adobe Flex, Microsoft Silverlight, …). Bien que JMeter ne fournisse pas d'implémentation de proxy native pour enregistrer ces protocoles, vous avez la possibilité d'enregistrer ces protocoles en implémentant un SamplerCreator personnalisé . Ce créateur d'échantillons traduira le format binaire en une sous-classe HTTPSamplerBase qui peut être ajoutée au cas de test JMeter. Pour plus de détails, voir "Étendre JMeter".
Serveur miroir HTTP ¶
Le serveur miroir HTTP est un serveur HTTP très simple - il reflète simplement les données qui lui sont envoyées. Ceci est utile pour vérifier le contenu des requêtes HTTP.
Il utilise le port par défaut 8081 .

Paramètres ¶
Paramètres ¶
headerA: valueA|headerB: valueB définirait headerA sur valueA et headerB sur valueB .
Vous pouvez également utiliser les paramètres de requête suivants :
Paramètres ¶
Affichage des propriétés ¶
L'affichage des propriétés affiche les valeurs des propriétés System ou JMeter. Les valeurs peuvent être modifiées en saisissant un nouveau texte dans la colonne Valeur.

Paramètres ¶
Échantillonneur de débogage ¶
L'échantillonneur de débogage génère un échantillon contenant les valeurs de toutes les variables et/ou propriétés JMeter.
Les valeurs sont visibles dans le volet Afficher les données de réponse de l'écouteur de l' arborescence des résultats .

Paramètres ¶
Déboguer le post-processeur ¶
Le post-processeur de débogage crée un sous-échantillon avec les détails des propriétés précédentes de l'échantillonneur, des variables JMeter, des propriétés et/ou des propriétés système.
Les valeurs sont visibles dans le volet Afficher les données de réponse de l'écouteur de l' arborescence des résultats .

Paramètres ¶
Fragment de test ¶
Le fragment de test est utilisé conjointement avec le contrôleur d' inclusion et le contrôleur de module .

Paramètres ¶
configurer le groupe de threads ¶
Un type spécial de ThreadGroup qui peut être utilisé pour effectuer des actions de pré-test. Le comportement de ces threads est exactement comme un élément Thread Group normal. La différence est que ces types de threads s'exécutent avant que le test ne procède à l'exécution de groupes de threads réguliers.

groupe de threads démontage ¶
Un type spécial de ThreadGroup qui peut être utilisé pour effectuer des actions post-test. Le comportement de ces threads est exactement comme un élément Thread Group normal. La différence est que ces types de threads s'exécutent une fois que le test a fini d'exécuter ses groupes de threads réguliers.

